
Last modified on 01 Oct 2021.
This is my note for the course (Structuring Machine Learning Projects). The codes in this note are rewritten to be more clear and concise.
👉 Course 1 – Neural Networks and Deep Learning.
👉 Course 2 – Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization.
👉 Course 3 – Structuring Machine Learning Projects.
👉 Course 4 – Convolutional Neural Networks.
👉 Course 5 – Sequence Models.
⭐ Case study (should read): Bird recognition in the city of Peacetopia.
⭐ Case study (should read): Autonomous driving (I copied it from this).
This course will give you some strategies to help analyze your problem to go in a direction that will help you get better results.
Introduction to ML Strategy
Why ML strategy?
- “ML strategy” = How to structure your ML project?
-
Ideas to improve your ML systems:
- Collect more data.
- Collect more diverse training set.
- Train algorithm longer with gradient descent.
- Try different optimization algorithm (e.g. Adam).
- Try bigger network.
- Try smaller network.
- Try dropout.
- Add L2 regularization.
- Change network architecture (activation functions, # of hidden units, etc.)
- However, don’t spend too much time to do one of above things, we need to go right direction!
Orthogonalization
- In orthogonalization, you have some controls, but each control does a specific task and doesn’t affect other controls.
- Chain of assumptions in ML:
- You’ll have to fit training set well on cost function (near human level performance if possible).
- If it’s not achieved you could try bigger network, another optimization algorithm (like Adam)…
- Fit dev set well on cost function.
- If its not achieved you could try regularization, bigger training set…
- Fit test set well on cost function.
- If its not achieved you could try bigger dev. set…
- Performs well in real world.
- If its not achieved you could try change dev. set, change cost function…
- You’ll have to fit training set well on cost function (near human level performance if possible).
Setting up your goal
Single number evaluation metric
- Advice : It’s better and faster to set a single number evaluation metric for your project before you start it.
- Example: instead of using both precision and recall, just use f1. Check this note.
- Dev set + single row number evaluation metric enough to make a choice!
Satisfying and Optimizing metric
- It’s difficult to set all parameters to a single row number evaluation metric set up (many) satisfying + (one) optimizing matrix.
- Satisfying (use threshold): satisfying this is enough.
- Optimizing: more important, it’s accuracy!
- Example: call “Hi Siri”,
- Accuracy: is it awoken? optimizing
- False positive: it’s awoken but we don’t call it! set the satisfying as less then 1 false positive per day!
Train/dev/test distributions
- The way we set the distribution of train / dev / test sets can impact much on the running time.
- Dev set = developement set / hold out cross validation set.
- Advice: Make dev set and test set come from the same distribution!
Size of the dev and test sets
- Old (less data, <100000): 70% train - 30% test or something like that.
- Now (big data): 98% - 1% - 1%.
- Test set: set your test set to be big enough to give high confiance in the overall performance of your system.
When to change dev/test sets and metrics
- Sometimes, we put our target a wrong place should change metric!
- Example: cat classification,
-
Algo A: 3% error but contains porn train / test error like this!
-
Algo B: 5% error but no porn human like this!
-
- This is actually an example of an orthogonalization where you should take a machine learning problem and break it into distinct steps:
- Figure out how to define a metric that captures what you want to do (place the target).
- Worry about how to actually do well on this metric (how to aim/shoot accurately at the target).
- Conclusion: if doing well on your metric + dev/test set doesn’t correspond to doing well in your application, change your metric and/or dev/test set.
Comparing to human-level performance
Why human-level performance?
- Reasons:
- ML algos are now work better & easier (than the past) only them is not enough need human-level performance (HLP).
- Workflow of building ML system wanna more efficient? try to do something that human can also do.
- Bayes error = best possible error (theory).
- After surpassing HLP, it’s slow down, why?
- HLP is very closed to Bayes optimal error. Ex: we can recognize things in blur.
- Whenever under HLP, there are certain tools to use to improve the performance but there is no tool to do after surpassing HLP.
- So long as ML is worse than HLP, you can:
- Get labeled data from human.
- Gain insight from manual error analysis: why did a person get this right?
- Better analysis of bias / variance.
Avoidable bias
- Sometimes we don’t want algo works TOO WELL on the training set use HLP.
- Example: cat recognition gives 2 different results (but the same gap between train & test)
-
Big gap between train and human. focus on reducing bias (bigger NN, run training longer,…) Underfitting!
Humans 1% 1% Training error 8% 8% Dev Error 10% 10% -
Small gap between train and human. focus on reducing variance Overfitting!
Humans 1% 7.5% Training error 8% 8% Dev Error 10% 10%
-
- Based on the human error decide whether high/low error bias / variance reduction!
- Gap between human & training Avoidable bias.
- Gap between training & test Variance!
Understanding human-level performance
- Use the nearest value to Bayes error as a human level error! (the smallest)
- The way we choose HL error sometimes can impact the way we improve our algo (bias or variance reduction)
- Use human level error as a proxy of Bayes error!
Surpassing human-level performance
- When training error less than human error, it’s difficile to decide what’s avoidable bias!
- In some problems, deep learning has surpassed human-level performance. Example: Online advertising, Product recommendation, Loan approval. Structured data.
- In natural perception tasks (speech recognition, NLP,…): ML surpasses human!
- In short:
- Machine > human structured data.
- Machine > One person some natural perception tasks.
- Machine > human natural perception tasks.
Improving your model performance
- The two fundamental asssumptions of supervised learning:
- You can fit the training set pretty well. This is roughly saying that you can achieve low avoidable bias.
- The training set performance generalizes pretty well to the dev/test set. This is roughly saying that variance is not too bad.
- To improve your deep learning supervised system follow these guidelines:
- Look at the difference between human level error and the training error - avoidable bias.
- Look at the difference between the dev/test set and training set error - Variance.
- If avoidable bias is large you have these options:
- Train bigger model.
- Train longer/better optimization algorithm (like Momentum, RMSprop, Adam).
- Find better NN architecture/hyperparameters search.
- If variance is large you have these options:
- Get more training data.
- Regularization (L2, Dropout, data augmentation).
- Find better NN architecture/hyperparameters search.
Error Analysis
Carrying out error analysis
- Error Analysis = manually examining mistakes that your algorithm is making can give you insight what to do next.
-
Example: in cat recognition, there are some factors affecting Consider a table ERROR ANALYSIS Evaluate multiple ideas in parallel,
Image Dog Great Cats blurry Instagram filters Comments 1 ✓ ✓ Pitbull 2 ✓ ✓ ✓ 3 Rainy day at zoo 4 ✓ …. % totals 8% 43% 61% 12% - We focus on Great Cats and blurry (have much influence).
- To carry out error analysis you should find a set of mislabeled examples in dev set look at mislabeled: False Positive or False Negative (number of errors) decide if to create a new category?
Cleaning up incorrectly labaled data
- In training: DL algo is robust to random errors we can ignore them!
- However, DL algo is LESS robust to systematic errors.
- Solutions: Using table Error Analysis to decide what types of error to focus in the next step (base of their fraction of errors in the total of errors).
- (Recall) The purpose of dev set is to help you select between 2 classifier A and B.
- If you decide to fix labels:
- Apply the same process to dev and test sets and make sure they come from the same distribution!
- Examine also on examples got right (not only on the ones got wrong) otherwise, we have overfitting problem!
- Train vs dev/test may have different distribution No need to be corrected mislabeled on training set!
When starting a new project?
Advice: Build your first system quickly and then iterate!!
- Quickly set up dev/test sets + metric.
- Build initial system quickly.
- Check bias analysis and Error analysis Priopritize the next step!
Mismatched training and dev/test set
Training & testing on different distribution
- Example: training (photos from internet, 200K), dev & test (photos from phone, 4K).
- Shouldn’t: Shufflt all 204K and split into train/dev/test!
- Should:
- Train - 200K (web) + 2K (mobile).
- Dev = Test = 0.5K (mobile).
Bias and Variance with mismatched data dist
- Sometimes, dev err > training err (possibly) the data in dev is more difficult to predict than the data in training.
- When comming from training err to dev err:
- The algo saw data in training set but not in dev set.
- The distribution of data in dev set is different!
- IDEA: create a new "train-dev" set which has the same distribution as training data but not used for training.
- Keys to be considered: Human error, Train error, Train-dev error, Dev error, Test error:
- Avoidable bias = train - human.
- Variance problem = train-dev - train
- Data mismatch = dev - train-dev
- Overfitting to dev set = test - dev
- If there is a huge gap between dev & test err overtune to the dev set may need to find a bigger dev set!
- Example 1: A high variance problem! (train/train-dev big, train-dev/dev small)
- Human error: 0%
- Train error: 1%
- Train-dev error: 9%
- Dev error: 10%
- Example 2: data mismatch problem (train/train-dev small, train-dev/dev big)
- Human error: 0%
- Train error: 1%
- Train-dev error: 1.5%
- Dev error: 10%
- Example 3: avoidable bias problem (because training err is much worse than human level, others are small)
- Human error: 0%
- Train error: 10%
- Train-dev error: 11%
- Dev error: 12%
- Example 4: Avoidable bias problem and mismatch problem. (human/train big, train-dev/dev big)
- Human error: 0%
- Train error: 1%
- Train-dev error: 1.5%
- Dev error: 10%
-
Remark: most of the time, the errs are decreasing from human to test. However if (sometimes) dev > train-dev, we rewrite all above errors in to a new table like this,
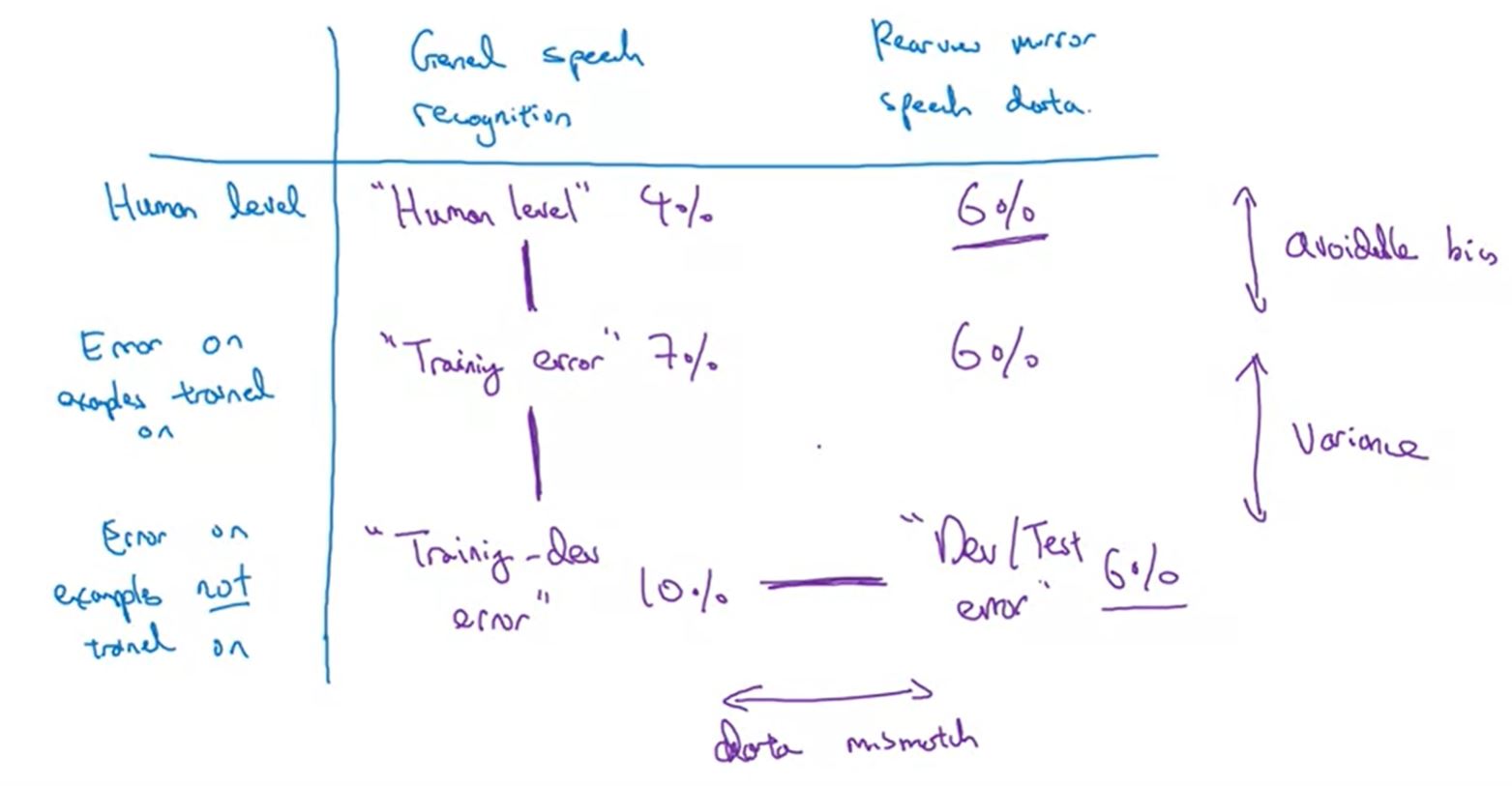 Error table. Image from the course.
Error table. Image from the course.- We find by hand 2 6% errors to consider the quality of dev/test err. In the figure, your figure is infact GOOD!
Addressing data mismatch
- Addressing data mismatch (don’t garantee it will work but you can try):
- Carry out manually error analysis try to understand difference between training and dev/test errors.
- Make the training data more similar or collect more data similar to dev/test set.
- Artificial data synthesis:
- “the quick brown fox jumps over the lazy dog” shortest sentence contains all A-Z letters in English.
- Create manually data (combine 2 different types of data). However, BE CAREFUL if one of 2 data is much smaller to the other. It may be overfitting to the smaller!
Learning from multiple tasks
Transfer learning
- IDEA: already trained on 1 task (Task A) + don’t have enough data on the current task (Task B) we can apply the trained network on the current one.
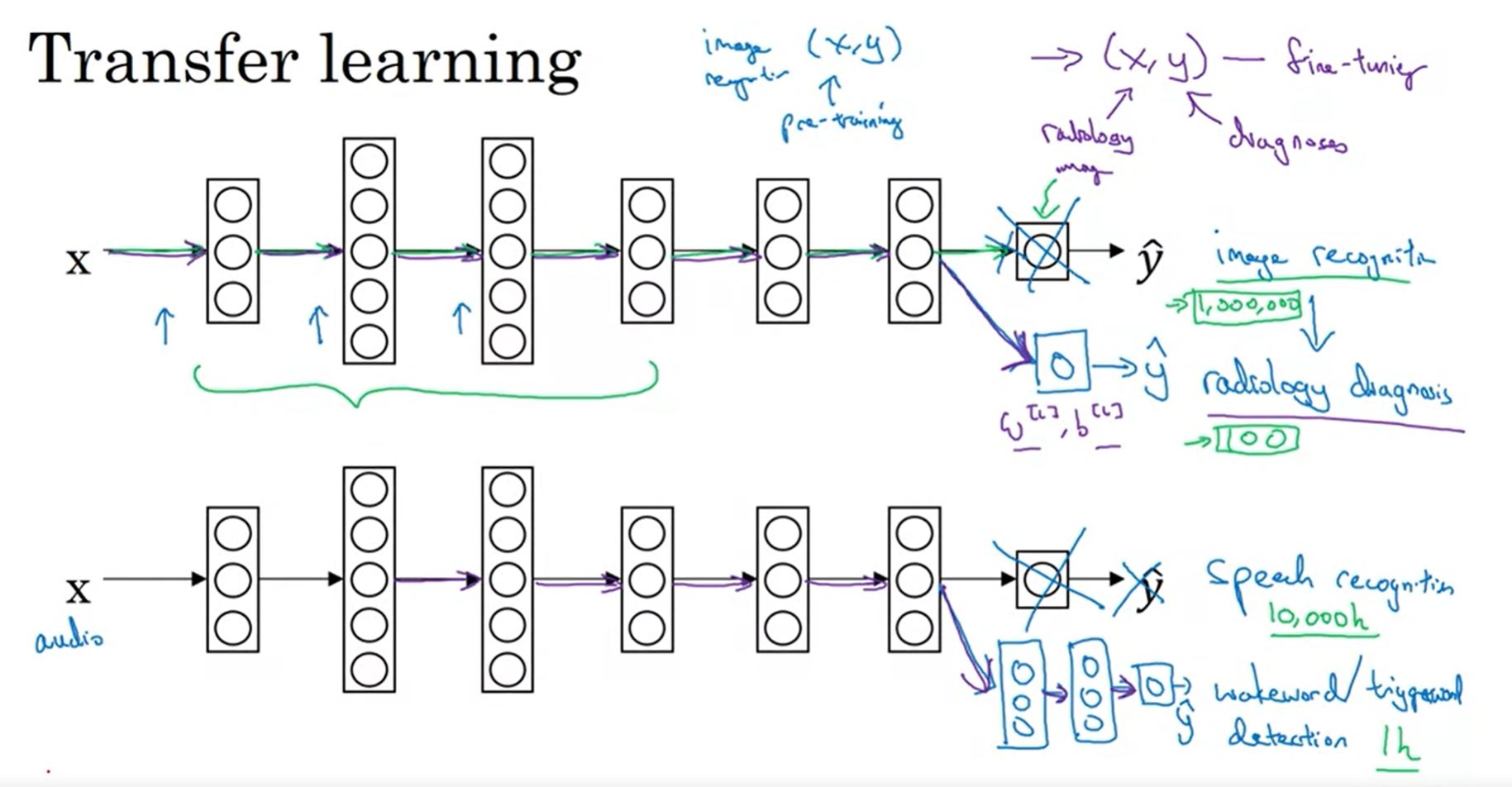 Transfer learning. Image from the course.
Transfer learning. Image from the course.
- To do transfer learning, delete the last layer of NN and it’s weights and:
- Option 1: if you have a small data set - keep all the other weights as a fixed weights. Add a new last layer(-s) and initialize the new layer weights and feed the new data to the NN and learn the new weights.
- Option 2: if you have enough data you can retrain all the weights.
- Pretraining = training on task A.
- Fine-tuning = using pretrained weights + use new data to train task B.
- This idea is useful because some of layers of trained NN contain helpful information for the new problem.
- Transfer learning makes sense when (e.g. from A to B):
- Task A and B have the same input X.
- You have a lot more data for task A than task B.
- Low level features from A could be helpful for learning B.
Multi-task learning
- 1 NN do several things at the same time and each of these tasks helps hopefully all of the other tasks!
- Example: Autonomous driving example Detect several things (not only 1) at the same time like: pedestrians, other cars, stop signs, traffic lights,…
 Multi-task learning. Image from the course.
Multi-task learning. Image from the course.
- We use Logistic Regression for the last layer. It’s DIFFERENT from softmax regression because in this case, we need to determine more than 2 labels!
- If there are some infos unclear in Y (e.g. don’t know if there is a traffic light or not?), we consider only the rest and just ignore the unclear!
- Multi-task makes sense when (e.g. from A to B):
- Training on a set of tasks that could benefit from having shred lover-level features.
- Usually: amount of data you have for each task is quite similar.
- Can train a big enough NN to do well on all the task.
- In general (have ENOUGH DATA), multi-task gives better performances!
- Other remarks:
- Multi-task learning (usually) works good in object detection.
- (Usually) transfer learning is USED MORE OFTEN (an better) than multi task learning!
End-to-end deep learning
- There have been some data processing system require multiple stages of processing. End-to-end does take all of them into 1 NN.
-
Example: speech recognition from English to French: this case, end-to-end works better than separated problems because it has enough data!
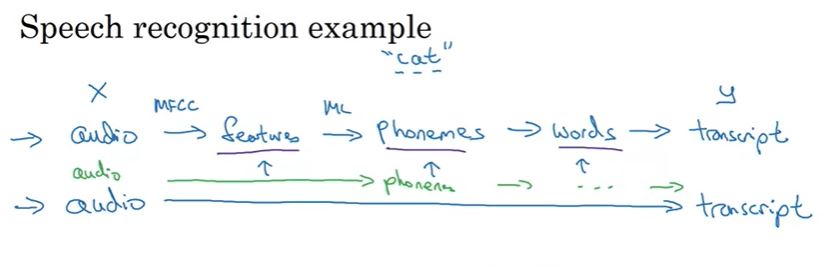 End-to-end learning. Image from the course.
End-to-end learning. Image from the course. - Example: auto open gate system: in this case, separated task is better end-to-end.
- Determine the head.
- Determine the name.
- When end-to-end works, it works very well!
- Pros & Cons:
- Pros:
- Let the data speaks.
- Let hand-designing of components needed.
- Cons:
- May need a lot of data.
- Excludes potentially useful hand-designing components.
- Pros:
- If having enough data can think of using end-to-end!
- Advice: carefully choose what type of mapping depends on what tasks you can get data for!
👉 Course 4 – Structuring Machine Learning Projects.