
Last modified on 01 Oct 2021.
This is my note for the course (Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization). The codes in this note are rewritten to be more clear and concise.
👉 Course 1 – Neural Networks and Deep Learning.
👉 Course 2 – Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization.
👉 Course 3 – Structuring Machine Learning Projects.
👉 Course 4 – Convolutional Neural Networks.
👉 Course 5 – Sequence Models.
This course will teach you the “magic” of getting deep learning to work well. Rather than the deep learning process being a black box, you will understand what drives performance, and be able to more systematically get good results. You will also learn TensorFlow.
Initialization step
layers_dims contains the size of each layer from to .
zero initialization
parameters['W'+str(l)] = np.zeros((layers_dims[l], layers_dims[l-1]))
parameters['b'+str(l)] = np.zeros((layers_dims[l], 1))
- The performance is really bad, and the cost does not really decrease.
- initializing all the weights to zero ⇒ failing to break symmetry ⇒ every neuron in each layer will learn the same thing ⇒ for every layer ⇒ no more powerful than a linear classifier such as logistic regression.
Random initialization
To break symmetry, lets intialize the weights randomly.
parameters['W'+str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) * 10 # <- LARGE (just an example of SHOULDN'T)
parameters['b'+str(l)] = np.zeros((layers_dims[l], 1))
- High initial weights ⇒ The cost starts very high (near 0 or 1 or infinity).
- Poor initialization ⇒ vanishing/exploding gradients ⇒ slows down the optimization algorithm.
- If you train this network longer ⇒ better results, BUT initializing with overly large random numbers ⇒ slows down the optimization.
He initialization
Multiply randomly initial with . It’s similar to Xavier initialization in which multipler factor is
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) * np.sqrt(2./layers_dims[l-1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
Regularization step
To reduce the overfitting problem.
L2 regularization
L2_regularization_cost = 0
for l in range(1, L+1):
L2_regularization_cost += 1/m * lambd/2 * (np.sum(np.square(W[l]))
- The standard way. Modify cost function from, to
- The value of is a hyperparameter that you can tune using a dev set.
- L2 regularization makes your decision boundary smoother. If is too large, it is also possible to “oversmooth”, resulting in a model with high bias.
Dropout
# [Forward] An example at layer 3
D3 = np.random.rand(A3.shape(0), A3.shape(1)) < keep_drop
A3 *= D3
A3 /= keep_drop
# [Backprop]
dA3 *= D3
dA3 /= keep_drop
- Dropout is a widely used regularization technique that is specific to deep learning.
- Randomly shuts down some neurons in each iteration.
- When you shut some neurons down, you actually modify your model. The idea behind drop-out is that at each iteration, you train a different model that uses only a subset of your neurons.
- With dropout, your neurons thus become less sensitive to the activation of one other specific neuron, because that other neuron might be shut down at any time.
- Don’t apply dropout to the input layer or output layer.
- Use dropout during training, not during test time.
- Apply dropout both during forward and backward propagation.
Gradient checking
- To answer “Give me a proof that your backpropagation is actually working!”
- We are confident on computing but .
- Use to compute an approximation of and compare with .
Optimization algorithms
Intuition:
- Gradient Descent: go down the hill.
- Momentum / RMSprop / Adam: which direction?
Mini-batch gradient descent
- Problem: NN works great on big data but many data leads to slow the training ⇒ We need to optimize!
- Solution: Divide into smaller “mini-batches” (for example, from 5M to 5K of 1K each).
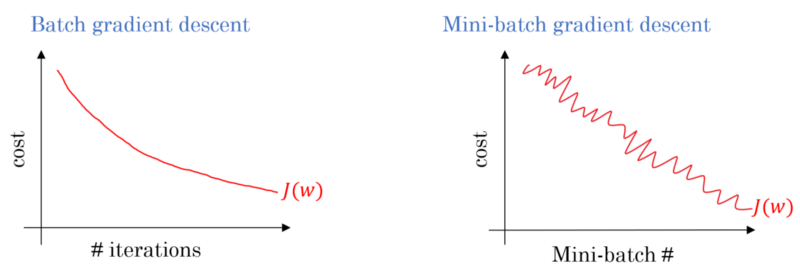 Different between mini-batch and normal batch on the cost function. It’s oscillated for mini-batch because the cost may be large for this mini-batch but small for the others. Image from the course.
Different between mini-batch and normal batch on the cost function. It’s oscillated for mini-batch because the cost may be large for this mini-batch but small for the others. Image from the course.
Notations
- : th training example.
- : value in th layer.
- : index of different mini-batches.
Algorithm
X = data_input
Y = labels
parameters = initialize_parameters(layers_dims)
for i in range(0, num_iterations): # loop through epoches: to get the convergence
for t in range(0, num_batches): # loop through the batches
# Forward propagation
a, caches = forward_propagation(X[:,t], parameters)
# Compute cost
cost += compute_cost(a, Y[:,t])
# Backward propagation
grads = backward_propagation(a, caches, parameters)
# Update parameters.
parameters = update_parameters(parameters, grads)
How to build mini-batches?
We need 2 steps:
- Shuffle: shuffle columns (training examples) correspondingly between and . The shuffling step ensures that examples will be split randomly into different mini-batches.
- Partition: choose a batch size and take mini-batches. Note that, the last batch may be smaller than the others.
Type of mini-batch
There are 3 types based on the size of batches:
- Batch Gradient Descent () : entire training examples, i.e. .
- Stochastic Gradient Descent () : every training example is it own a mini-batch ( mini batches).
- .
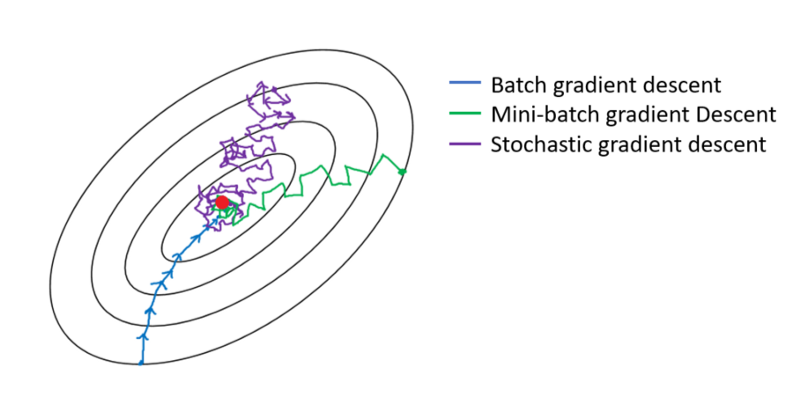 Different between 3 types of mini-batch. Image from the course.
Different between 3 types of mini-batch. Image from the course.
Guideline:
- If small training set (): using batch gradient descent.
- Typical mini-batch sizes:
- Make sure mibi-batch size in CPU/GPU memory!
Exponentially weighted averages
- It’s faster than Gradient Descent!
- Example (temperature in London):
- : the temperature on day .
- : the average temp of each day. It’s called exponential average over days temperature.
- E.g. days temperature; days temperature.
- larger ⇒ smoother average line because we consider more days. However, curve is now shifted further to the right.
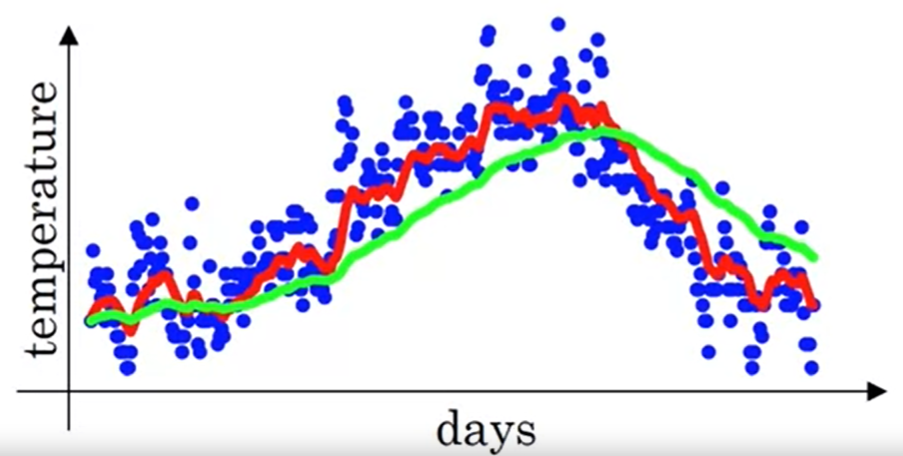 Exponentially weighted average curves: red line (), green line (). Image from the course.
Exponentially weighted average curves: red line (), green line (). Image from the course.
- When is so large ⇒ adapts slowly to the changes of temperature (more latency).
- Why we call “exponentially”?
Bias correction
- Problem: the value of at the beginning of exp ave curves may be lower than what we expect. For example, with , we have instead of .
- Solution: Instead of using , we take
- When is large ⇒
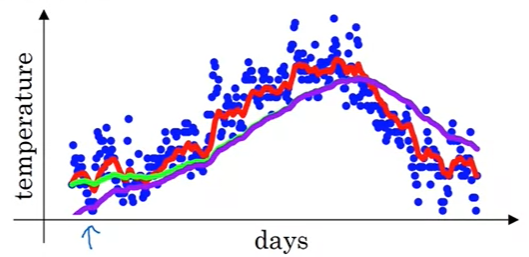 Bias correction for the green line, it’s effective at the beginning of the line, with bigger , green and violet are overlapped. Image from the course.
Bias correction for the green line, it’s effective at the beginning of the line, with bigger , green and violet are overlapped. Image from the course.
- In practice, we don’t really see people bothering with bias correction!
Gradient Descent with Momentum
- It’s faster than Gradient Descent!
- Why: when we use mini-batch, there are oscillation, momentum helps use reduce this.
- One sentence: compute the exponential weighted average of your gradient ⇒ use that gradient to update your weights instead.
- Idea: Momentum takes into account the past gradients to smooth out the update. We will store the ‘direction’ of the previous gradients in the variable . Formally, this will be the exponentially weighted average of the gradient on previous steps.
- Intuition: You can also think of as the “velocity” of a ball rolling downhill, building up speed (and momentum) according to the direction of the gradient/slope of the hill.
- like “acceleration”.
- like “velocity”.
- likes “friction”.
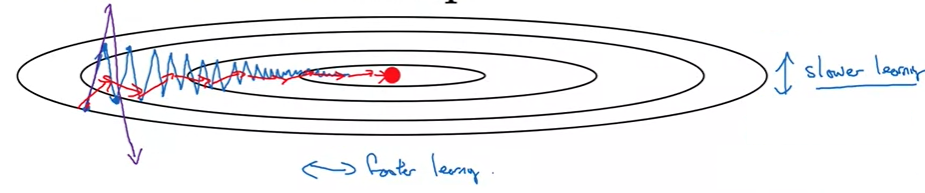 We want slower learning in vertial direction and faster in horizontal direction. Image from the course.
We want slower learning in vertial direction and faster in horizontal direction. Image from the course.
- Algorithm: on iteration :
- Compute on current mini-batch.
- .
- .
- .
- .
- Implementation:
- Try to tune between , commonly use .
- Don’t bother bias correction, NO NEED.
- Don’t need in the formulas but Andrew prefer to keep it!
- Bigger , smaller in vertical direction.
RMSprop
- It’s “Root Mean Square propagation”.
- Algorithm: on iteration ,
- Compute on current element-wise mini-batch.
- .
- .
- .
- .
- We choose if is too small, otherwise .
- In practice: are very high dimensional vectors.
Adam Optimization
- It’s “Adaptive Moment Estimation”.
- One of the most effective optimization algorithm for training NN. It’s commonly used and proven to be very effective for many different NN of a very wide variety of architectures.
- Adam = Momentum + RMSprop.
- Implementation: on iteration ,
- Compute using current mini-batch.
- (Monentum) ; .
- (RMSprop) ; .
- ; .
- ; .
- ; .
- Initialization of the velocity is zero, i.e. .
- If , it’s standard gradient descent without momentum.
- Hyperparameter choices:
- = needs to be tuned, very important!
- (), first moment.
- (), second mement.
- .
Learning rate decay
- Idea: slowly reduce learning rate over time, it’s learning rate decay.
- Why? Below figure showes that, we need slower rate (smaller step) at the area near the center.
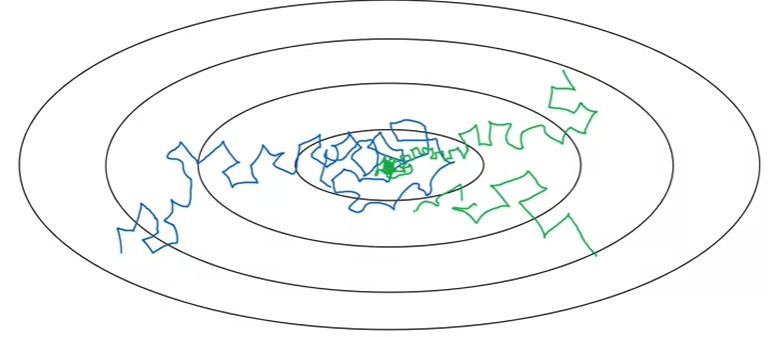 Example of learning rate decay. Image from the course.
Example of learning rate decay. Image from the course.
- Recall that, 1 epoch = 1 pass through data.
- Learning rate decay can be chosen 1 of below,
Problem of local optima
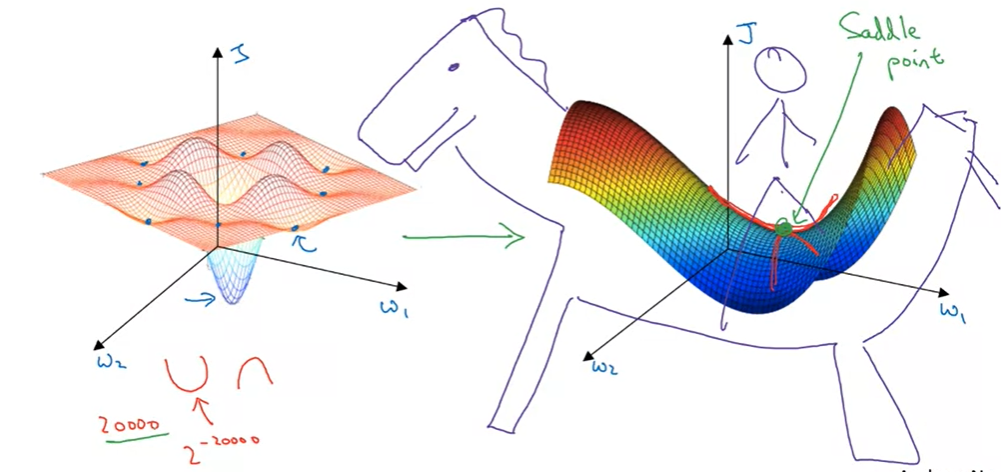 Local optima problem: local & right optima (left) and saddle point (right). Image from the course.
Local optima problem: local & right optima (left) and saddle point (right). Image from the course.
- In high dimension, you likely see saddle points than local optimum.
- Problem of plateau: a region where derivative is close to zero for a long time.
- Unlikely get stuck in a bad local optimal.
- Plateau can make learning slow: use Momentum, RMSprop, Adam.
Batch GD makes learning too long?
- Try better random initialization for weights.
- Try mini-batch GD.
- Try using Adam
- Try tuning learning rate .
Hyperparameter tuning
Tuning process
- There are many hyperparameters but some are more important than others!
- Learning rate (most important), #hiddien units, , mini-batch size (2nd important), #layers, learning decay,…
- Don’t use grid, use random!
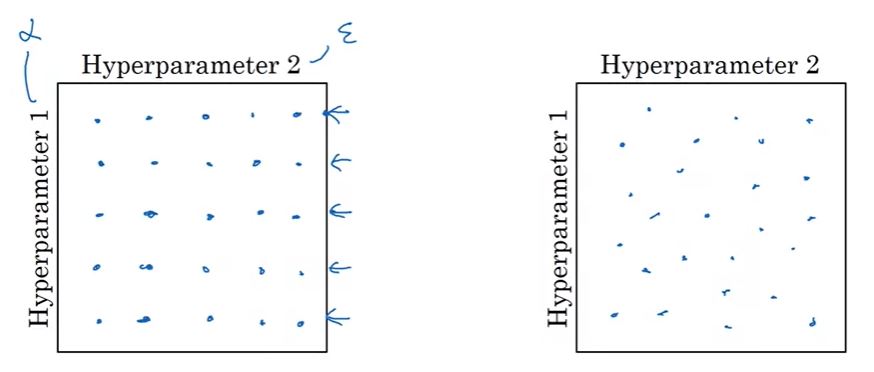 Tuning process. Don’t use grid (left), use random (right). Image from the course.
Tuning process. Don’t use grid (left), use random (right). Image from the course.
- Coarse to fine: find an area containing effective values ⇒ zoom in and take more points in that area,
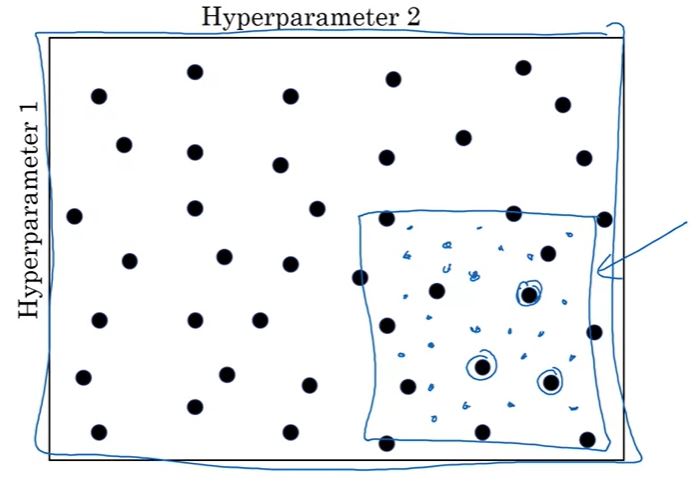 Coarse to fine: first try on a big square, then focus on the smaller one (blue). Image from the course.
Coarse to fine: first try on a big square, then focus on the smaller one (blue). Image from the course.
- Choose randomly but NOT mean uniform scale! We can choose uniformly on #hidden units, #layers, but not for the others (e.g. ).
- For , for example, we need to divide into equal “large” spaces and then use uniform.
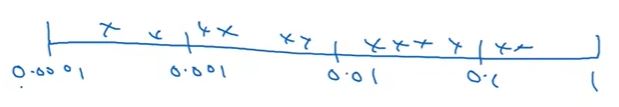 Appropriate scale for hyperparameters. Image from the course.
Appropriate scale for hyperparameters. Image from the course.
- Hyperparameters for exponentially weighted averages:
- We cannot try with values between because,
- : no much changes,
- : huge impact!
-
Consider instead!
- We cannot try with values between because,
In practice: Panda vs Caviar
- How to organize your hyperparameter search?
- Advice: Re-testing/Re-evaluating your hyperparameters at least once every several months.
- 2 ways:
- Babysitting one model (Panda): when we have huge data but weak CPU/GPU try very small number of models at a time. Check the performance step by step (cost function reduces…)
- In some domains like advertising, computer vision apps,…
- We call “panda” because panda has very few number of babies at a time (and in their life) try to keep them alike once at a time.
- Training many models in parallel (Caviar): when we don’t work on huge data + strong CPU/GPU. Try many models in parallel and choose the best performance!
- We call “Caviar” because of intuition.
- Babysitting one model (Panda): when we have huge data but weak CPU/GPU try very small number of models at a time. Check the performance step by step (cost function reduces…)
Batch Normalization
- Make NN much more robust to the choice of hyperparameters. doesn’t work for all NN but if it does, make training faster!
- One of the most important ideas in the rise of Deep Learning.
- Like we wanna normalize input to speed up learning, in this case, we wanna normalize (in the hidden layers)
Given some initial values in NN ,
- to get mean and STD .
- to have different other normal distribution.
Now, are learnable parameters of the model.
- If we choose different hidden units have other means & variances.
- Instead of using , we use .
- Difference between normalizing input and normalizing in hidden units:
- : after normalizing, .
- : after normalizing, various .
- Note that, in this case is different from in Adam optimization!
- We can use gradient descent to update and even use Adam/RMSprop/Momentum to update params , not just for Gradient Descent.
- In practice, we won’t have to implement Batch Norm step by step by ourself, programming framework (like Tensorflow) will do!
- In practice, Batch Norm is usually applied with mini-batch of your training set.
- Parameters: . We don’t need to consider becase it will be subtracted out in the process of normalization!
- Fitting Batch Norm into a NN: for goes through the number of mini-batches,
- Compute forward prop on .
- In each hidden layer, use Batch Norm to reparameter to .
- Use backprop to compute .
-
Update params (we can use Momentum / RMSprop / Adam):
- Sometimes, BN has a 2nd effect as a regularization technique but it’s unintended! We don’t use it for the purpose of regularization, use L1, L2 or dropout instead.
(Recall) Regularization: techniques that lower the complexity of a NN during training, thus prevent the overfitting.
Why BN works?
- Make weights in later / deeper layers be more robust to changing to the weights in the earlier layers.
- Covariate shift problem: suppose we have . If ’s distribution changes, it changes the result in much. We have to re-train our model.
- Example: “cat vs non-cat” problem. If we apply params from the model of “black cat vs non-cat” to the problem of “colored-cat vs non-cat”, it won’t work because distribution in “black cat” is different from “colored cat”.
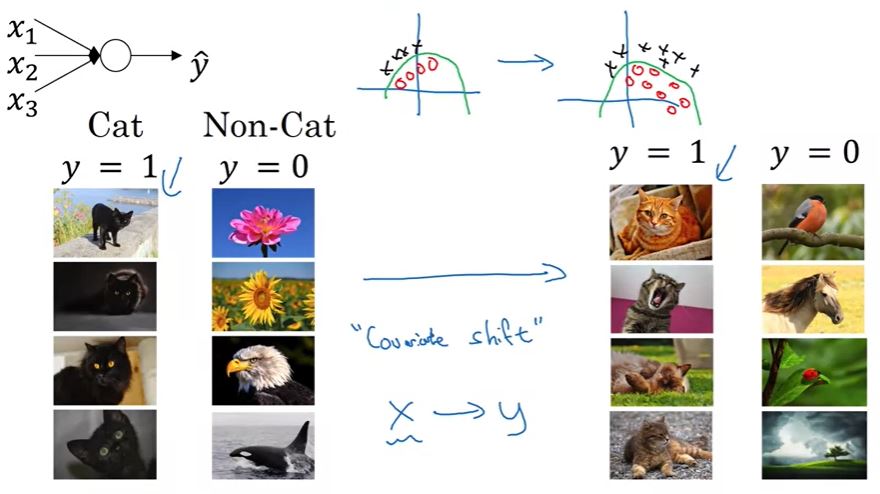 Covariate problem. Image from the course.
Covariate problem. Image from the course.
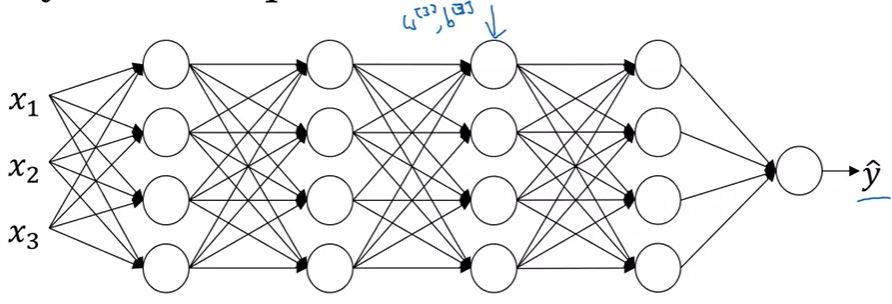 Why BN works?. Image from the course.
Why BN works?. Image from the course.
In the perspective of layer 3, it depends only on layer 2 If layers before layer 2 changes distribution of layer 2 changes covariate shift problem for layer 3 Batch Norm makes sure that mean and variance in layer 2 is always robust before going to layer 3!
Batch Norm in test time
- BN processes our data one min-batch at a time. However, in test time, you need to process the examples at a time. Need to adapt your network to do that.
- Idea: calculate using exponentially weighted average (across mini-batches). Other words,
- In the training time, we calculate (and store) also the in each mini-batch.
- Find (exponentially weighted average) of all mini-batches.
- Use this to find and (at each example ).
- Don't worry, it's easy to use with Deep Learning Frameworks.
Tensorflow introduction
Writing and running programs in TensorFlow has the following steps:
- Create Tensors (variables) that are not yet executed/evaluated.
- Write operations between those Tensors.
- Initialize your Tensors.
- Create a Session.
- Run the Session. This will run the operations you’d written above.
# create placeholders
x = tf.placeholder(tf.int64, name = 'x')
X = tf.placeholder(tf.float32, [n_x, None], name="X")
# initialize
W1 = tf.get_variable("W1", [25,12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b1 = tf.get_variable("b1", [25,1], initializer = tf.zeros_initializer())
There are two typical ways to create and use sessions in tensorflow:
- Method 1:
sess = tf.Session() # Run the variables initialization (if needed), run the operations result = sess.run(..., feed_dict = {...}) sess.close() # Close the session - Method 2:
with tf.Session() as sess: # run the variables initialization (if needed), run the operations result = sess.run(..., feed_dict = {...}) # This takes care of closing the session for you :)
What you should remember:
- Tensorflow is a programming framework used in deep learning
- The two main object classes in tensorflow are Tensors and Operators.
- When you code in tensorflow you have to take the following steps:
- Create a graph containing Tensors (Variables, Placeholders …) and Operations (
tf.matmul,tf.add, …) - Create a session
- Initialize the session
- Run the session to execute the graph
- Create a graph containing Tensors (Variables, Placeholders …) and Operations (
- You can execute the graph multiple times as you’ve seen in model()
- The backpropagation and optimization is automatically done when running the session on the “optimizer” object.
👉 Check more details about the codes in the notebook.
👉 Course 3 – Structuring Machine Learning Projects.