
Last modified on 01 Oct 2021.
What’s the idea of Random Forest?
Random forest consists a (large) number of decision trees operating together (ensemble learning). The class with the most votes from the trees will be chosen as the final result of the RF’s prediction. These decision tree models are relatively uncorrelated so that they can protect each other from their individual errors.
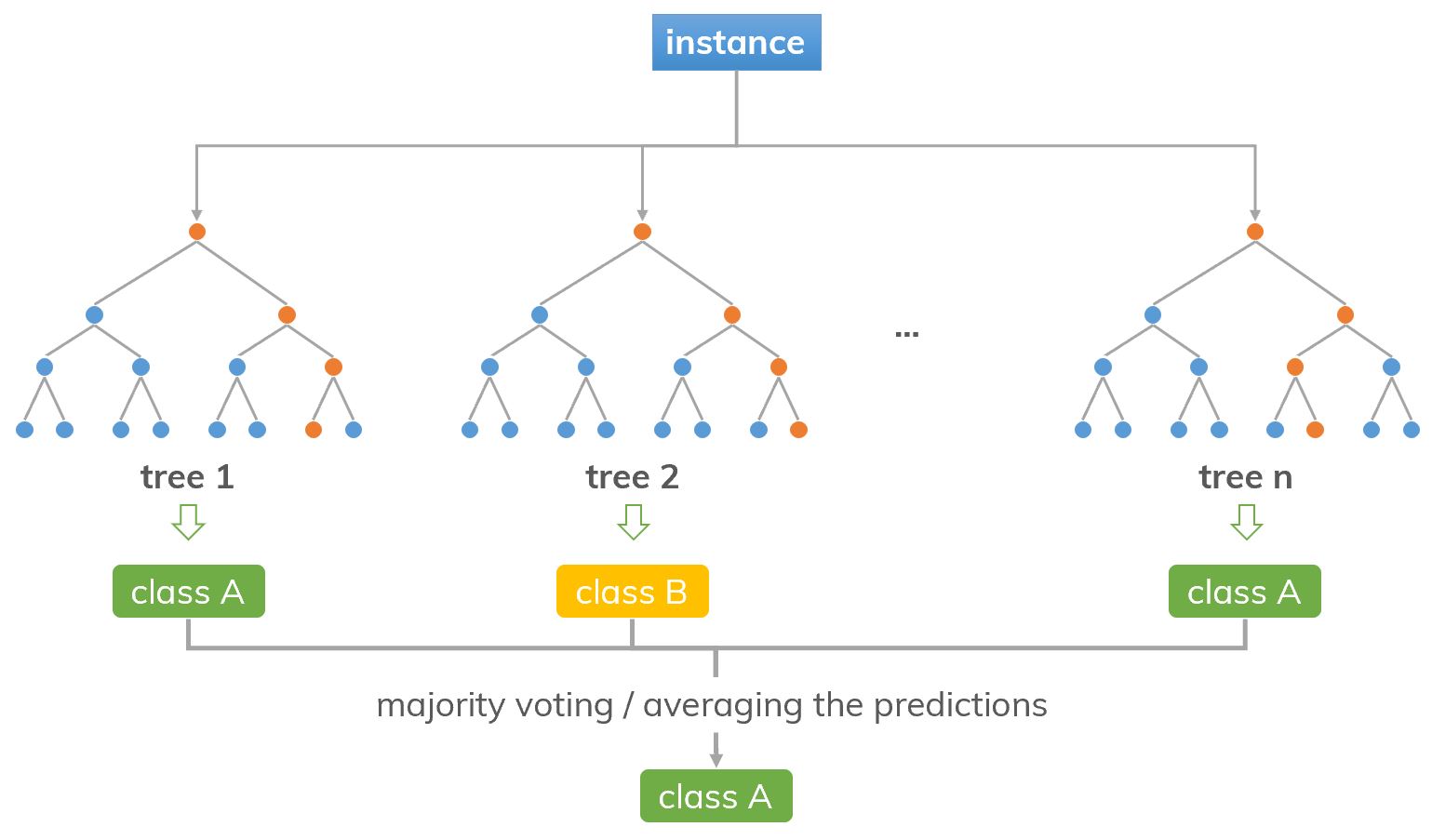 An illustration of the random forest’s idea.
An illustration of the random forest’s idea.
❓ How (decision) trees are chosen? RF ensures that the chosen trees are not too correlated to the others.
- Bagging: From a sample of size N, trees are chosen so that they also have size N with replacement. For example, if our training data was [1, 2, 3, 4, 5] (size 5), then we might give one of our tree the list [1, 2, 2, 5, 5] (with replacement).
- Feature randomness: The features in the original dataset are chosen randomly. There may be some trees that are lacking in some features.
So in our random forest, we end up with trees that are not only trained on different sets of data (thanks to bagging) but also use different features to make decisions[ref] .
For each tree, we can use decision tree classifier or decision tree regression depending on the type our problem (classification or regression).
When we use Random Forest?
- Decision tree algorithms easily lead to overfitting problems. Random forest algorithm can overcome this.
- Capable of both regression and classification problems.
- Handle a large number of features.
- Estimating which features are important in the underlying data being modeled[ref] .
- Random forest is capable of learning without carefully crafted data transformations[ref] .
- Output probabilities for classification problems.
Using RF with Scikit-learn
Random forest classifier
Load the library,
from sklearn.ensemble import RandomForestClassifier
A sample dataset:
iris = datasets.load_iris() # iris flowers
X = iris.data
y = iris.target
Create RF classifier(other parameters),
clf = RandomForestClassifier(criterion='entropy', # default is 'gini'
n_estimators=8, # number of trees (default=10)
n_jobs=-1) # number of processors being used ("-1" means "all")
If a problem has imbalanced classes, use class_weight="balanced".[ref]
Training & predict (other methods),
model = clf.fit(X, y)
model.predict([[ 5, 4, 3, 2]]) # returns: array([1])
model.predict_proba([[ 5, 4, 3, 2]]) # predict class probabilities
Random forest regression
# load libraries
from sklearn.ensemble import RandomForestRegressor
from sklearn import datasets
# sample: Boston Housing Data
boston = datasets.load_boston()
X = boston.data[:,0:2]
y = boston.target
# train
regr = RandomForestRegressor(random_state=0, n_jobs=-1)
model = regr.fit(X, y)
# predict
model.predict(<something>)
Select important features in Random Forest
Some premilinaries,
from sklearn.ensemble import RandomForestClassifier
# Load data
iris = datasets.load_iris()
X = iris.data
y = iris.target
# create a RF classifier
clf = RandomForestClassifier(random_state=0, n_jobs=-1)
Select feature importance[ref] ,
# Train model
model = clf.fit(X, y)
# Calculate feature importances
importances = model.feature_importances_
# load additional packages
import numpy as np
import matplotlib.pyplot as plt
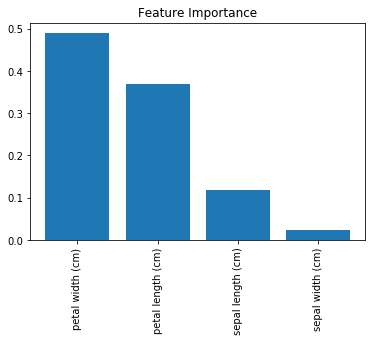
Visualize,
# Sort feature importances in descending order
indices = np.argsort(importances)[::-1]
# Rearrange feature names so they match the sorted feature importances
names = [iris.feature_names[i] for i in indices]
plt.figure()
plt.title("Feature Importance")
plt.bar(range(X.shape[1]), importances[indices])
plt.xticks(range(X.shape[1]), names, rotation=90)
plt.show()
Select features with importance greater than a threshold,[ref]
from sklearn.feature_selection import SelectFromModel
# Create object that selects features with importance greater than or equal to a threshold
selector = SelectFromModel(clf, threshold=0.3)
# Feature new feature matrix using selector
X_important = selector.fit_transform(X, y)
# Train random forest using most important features
model = clf.fit(X_important, y)
References
- Tony Yiu – Understanding Random Forest.
- Scikit-learn – Random Forest CLassifier official doc.
- Scikit-learn – Random Forest Regression official doc.
- Chris Albon – Titanic Competition With Random Forest.
- The Yhat Blog – Random Forests in Python.
- fast.ai – Introduction to Random Forest and a solution to “Bull Book for Bulldozers” problem on Kaggle.