
Last modified on 01 Oct 2021.
What’s the idea of Decision Tree Classifier?
The basic intuition behind a decision tree is to map out all possible decision paths in the form of a tree. It can be used for classification and regression (note). In this post, let’s try to understand the classifier.
Suppose that we have a dataset like in the figure below[ref, Table 1.2],
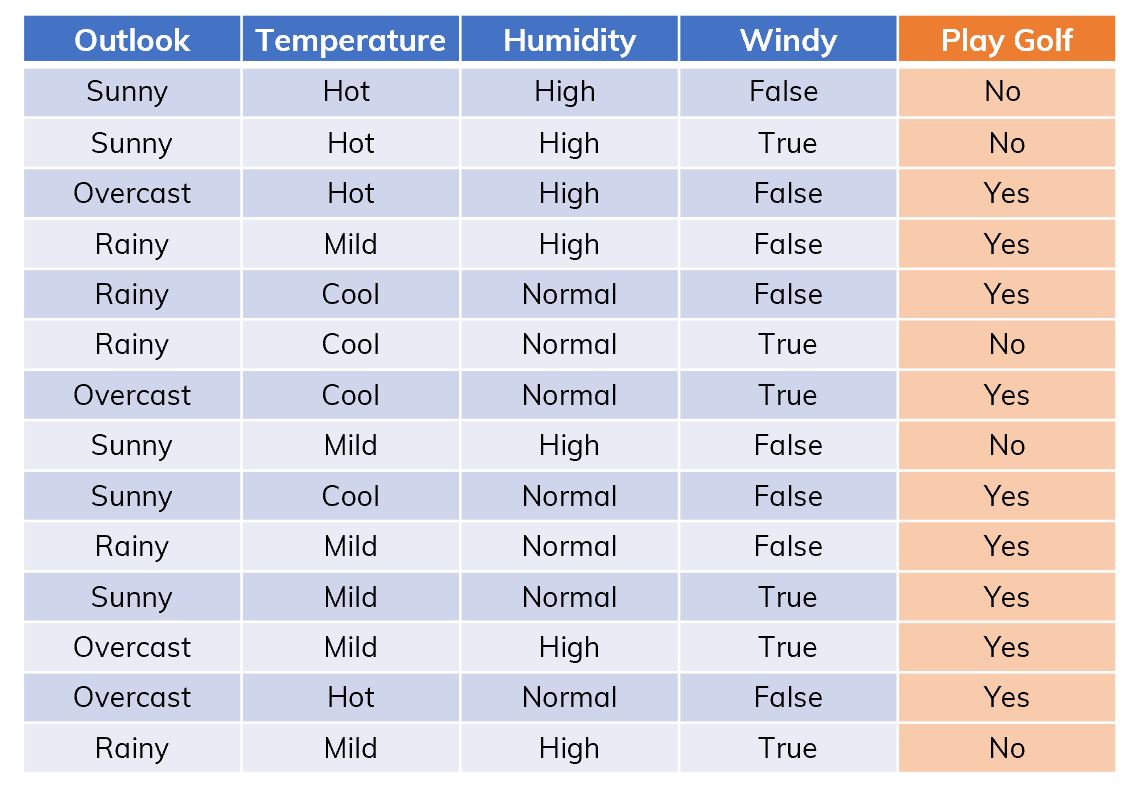 An example of dataset .
An example of dataset .
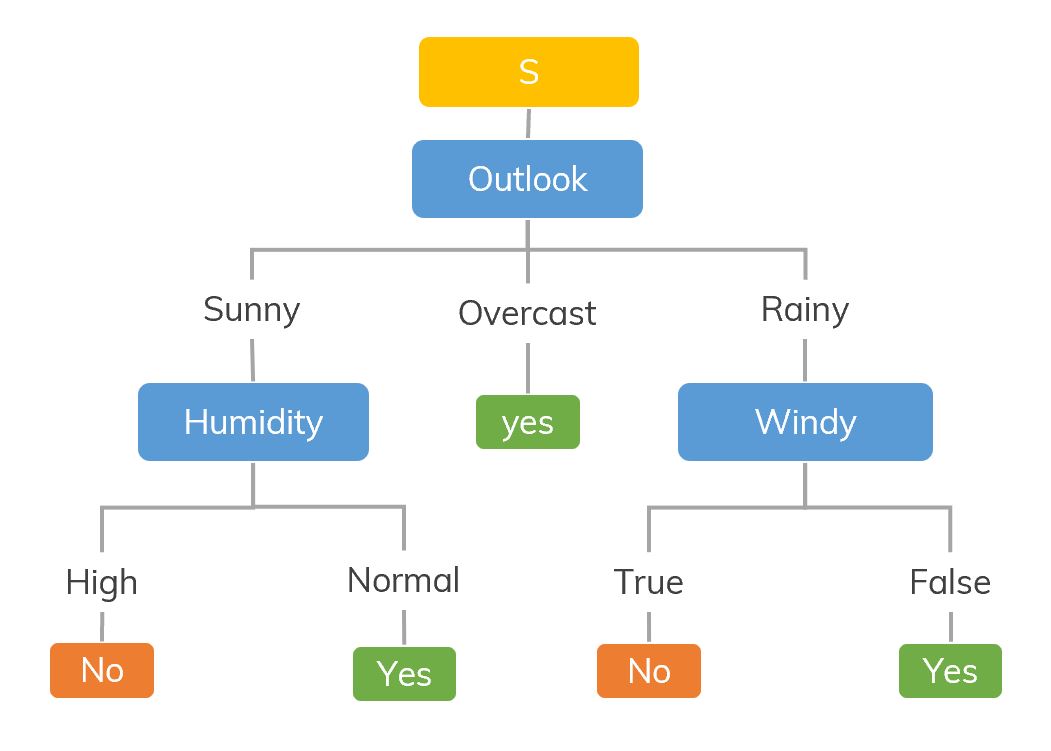 A decision tree we want.
A decision tree we want.
There are many algorithms which can help us make a tree like above, in Machine Learning, we usually use:
- ID3 (Iterative Dichotomiser): uses information gain / entropy.
- CART (Classification And Regression Tree): uses Gini impurity.
Some basic concepts
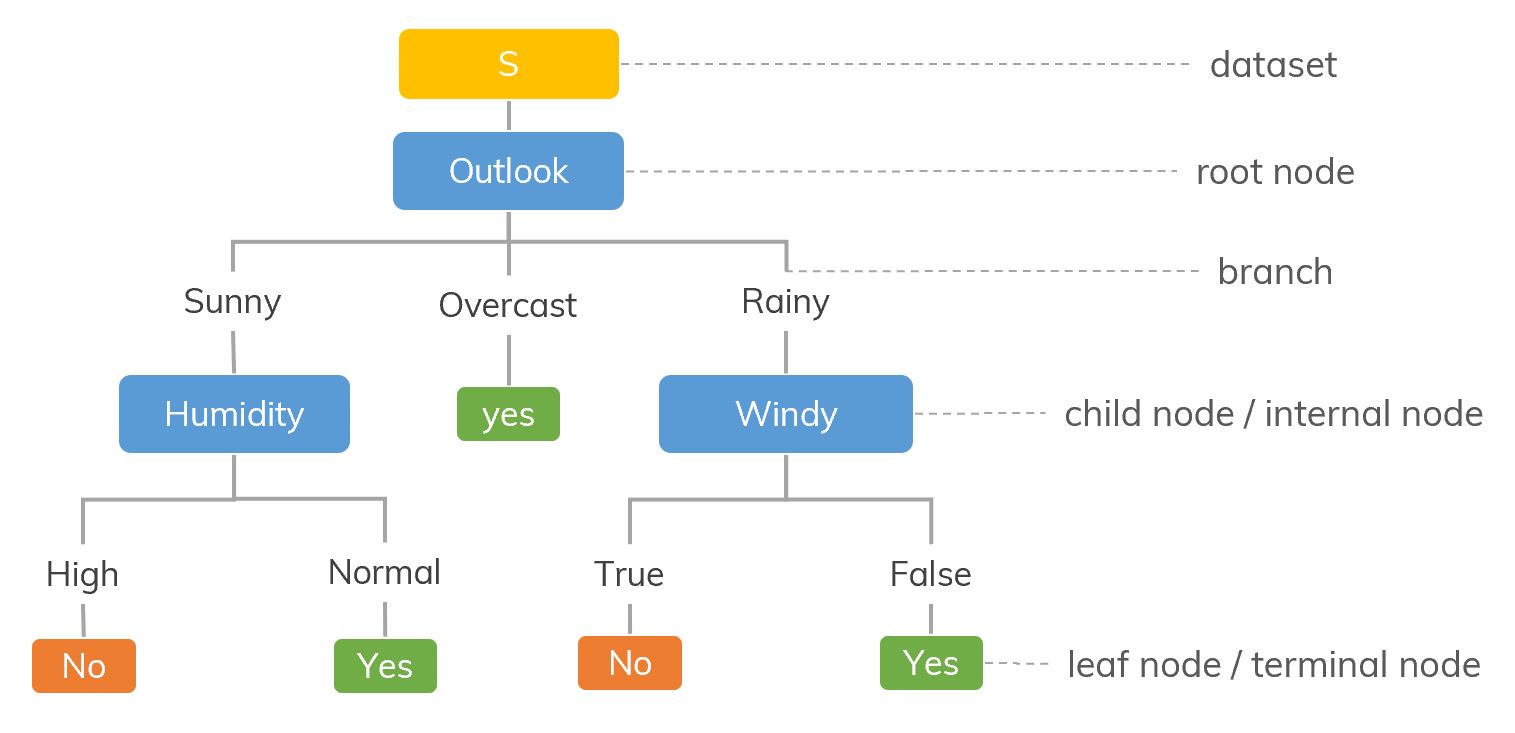
- Splitting: It is a process of dividing a node into two or more sub-nodes.
- Pruning: When we remove sub-nodes of a decision node, this process is called pruning.
- Parent node and Child Node: A node, which is divided into sub-nodes is called parent node of sub-nodes where as sub-nodes are the child of parent node.
ID3 algorithm
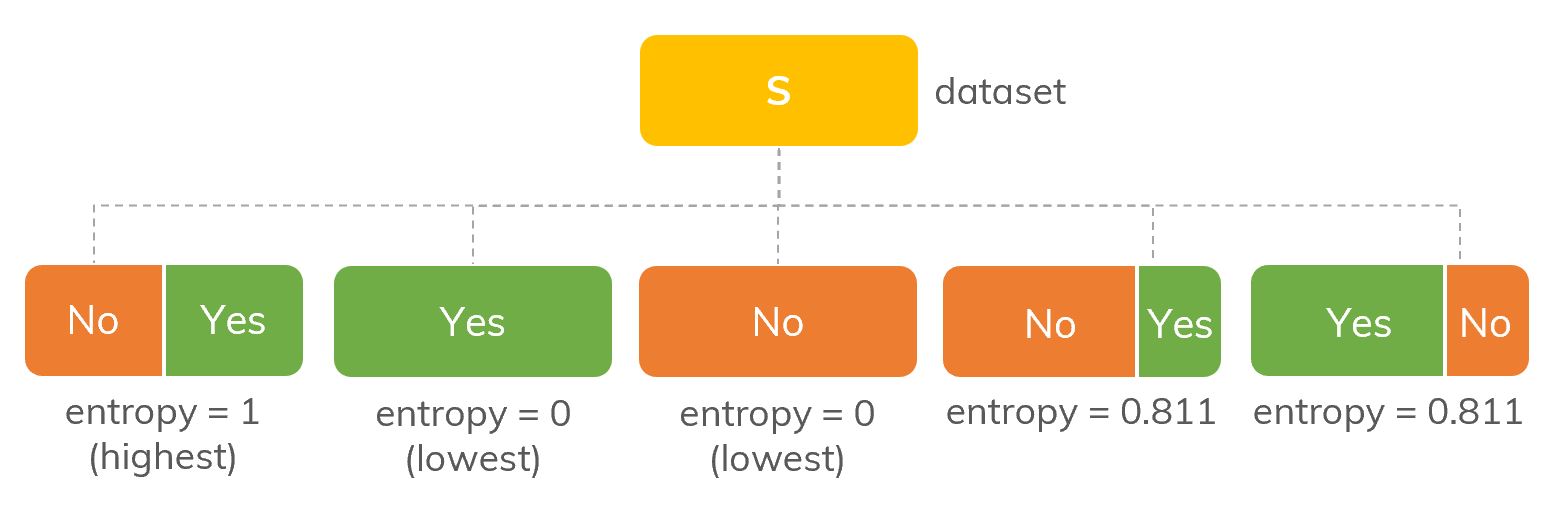 An illustration of entropy with different proportions of Yes/No in
An illustration of entropy with different proportions of Yes/No in  Graph of
Graph of 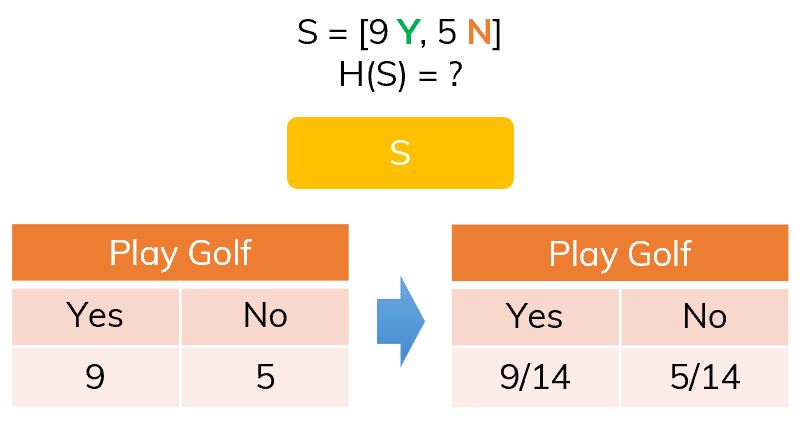 The frequency of classes in S.
The frequency of classes in S.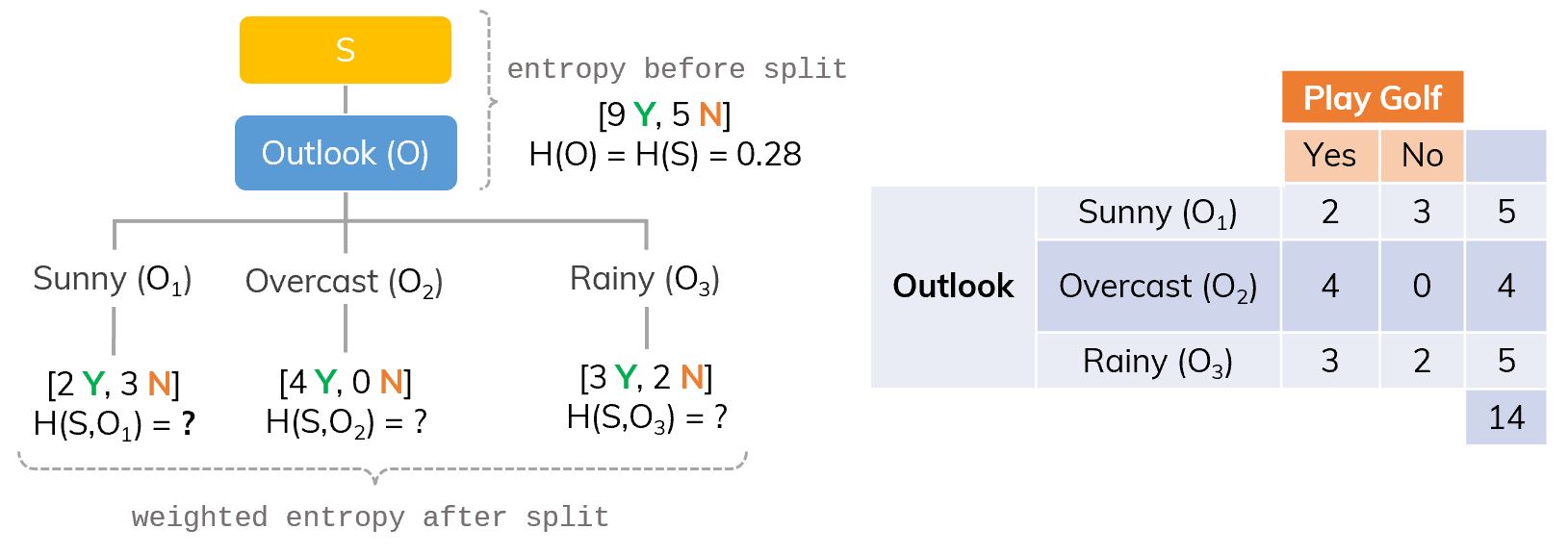 If we split S on Outlook (O), there will be 3 branches.
If we split S on Outlook (O), there will be 3 branches.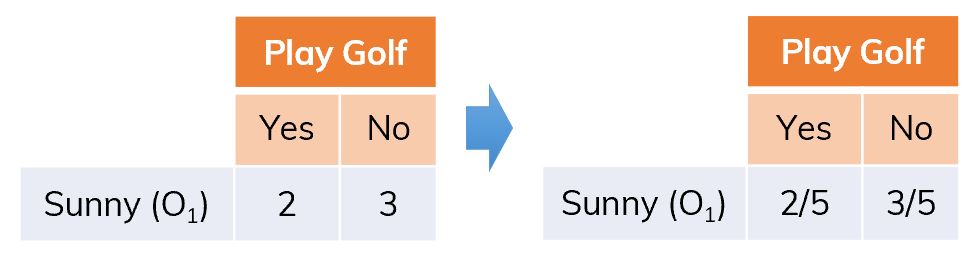 Only consider branch Sunny (
Only consider branch Sunny (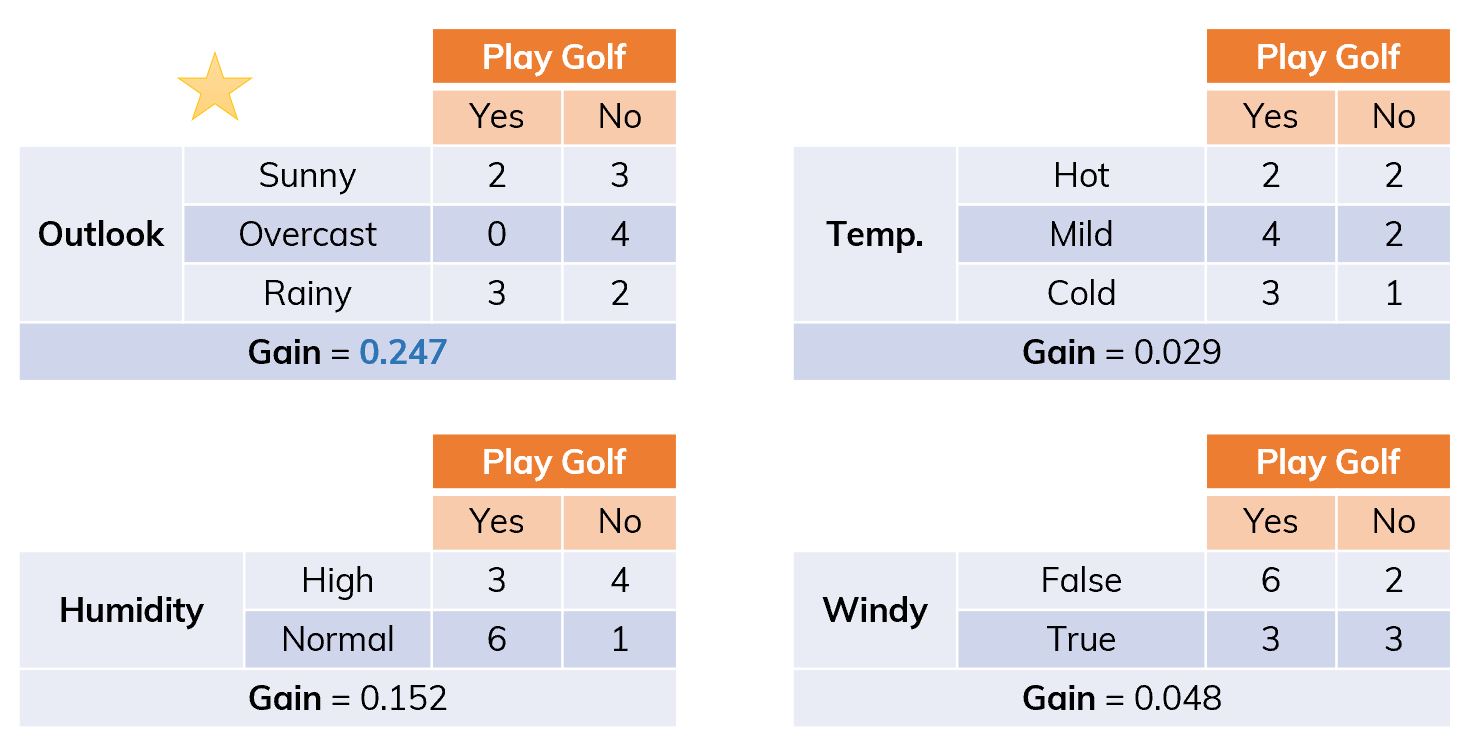 Dataset is split into different ways.
Dataset is split into different ways.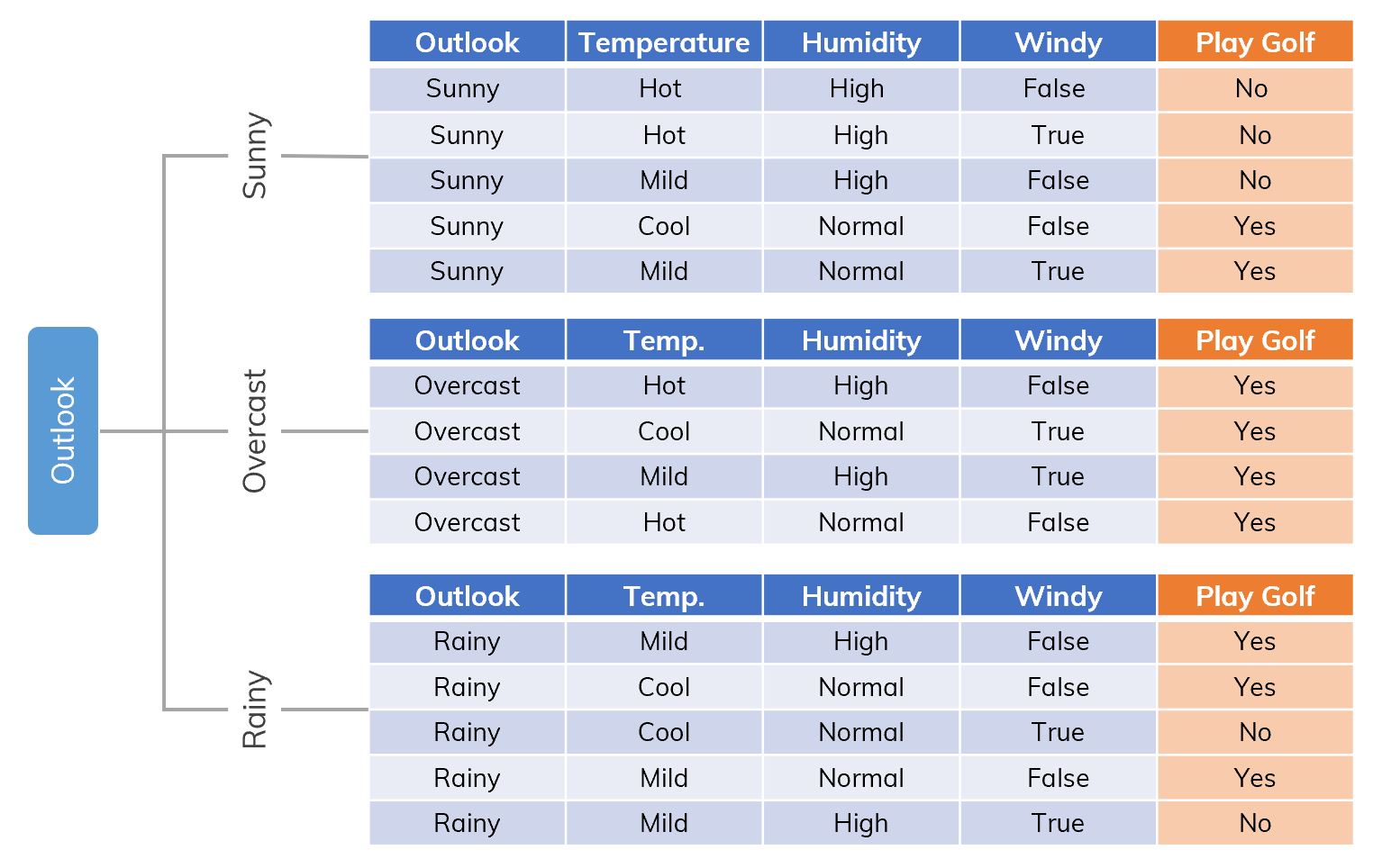 Dataset is split on Outlook.
Dataset is split on Outlook.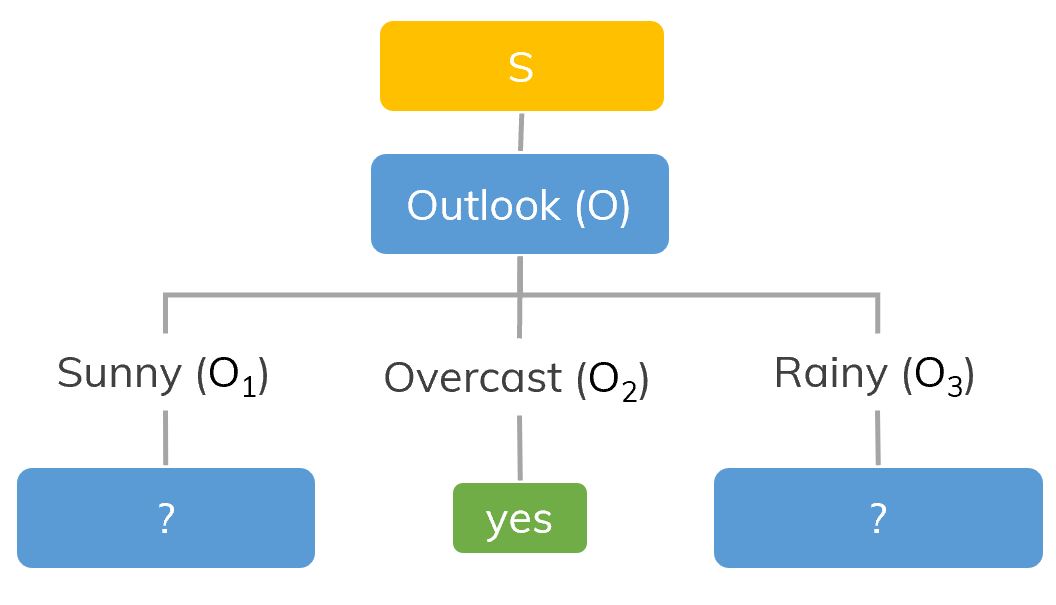 There are remaining Temperature, Humidity, Windy. Which attribute will be chosen next?
There are remaining Temperature, Humidity, Windy. Which attribute will be chosen next?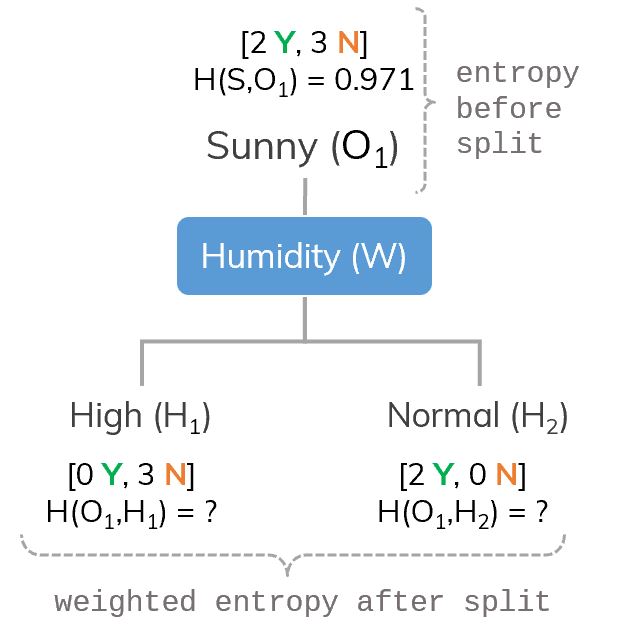 Consider branch
Consider branch 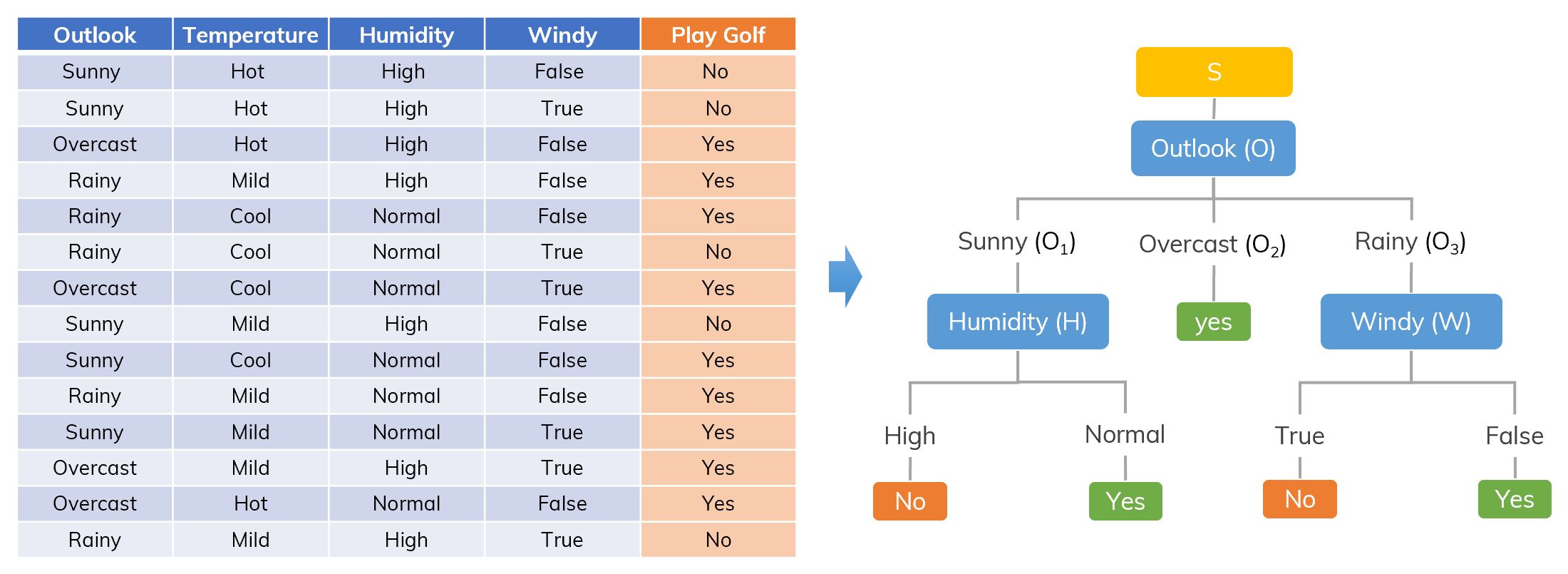
CART algorithm
 If we split S on Outlook (O), there will be 3 branches.
If we split S on Outlook (O), there will be 3 branches.Gini Impurity or Entropy? [ref]
- Most of the time, they lead to similar trees.[ref]
- Gini impurity is slightly faster.[ref]
- Gini impurity tends to isolate the most frequent class in its own branch of the tree, while entropy tends to produce slightly more balanced trees.
Good / Bad of Decision Tree?[ref]
Some highlight advantages of Decision Tree Classifier:
- Can be used for regression or classification.
- Can be displayed graphically.
- Highly interpretable.
- Can be specified as a series of rules, and more closely approximate human decision-making than other models.
- Prediction is fast.
- Features don’t need scaling.
- Automatically learns feature interactions.
- Tends to ignore irrelevant features.
- Non-parametric (will outperform linear models if relationship between features and response is highly non-linear).
Its disadvantages:
- Performance is (generally) not competitive with the best supervised learning methods.
- Can easily overfit the training data (tuning is required).
- Small variations in the data can result in a completely different tree (high variance).
- Recursive binary splitting makes “locally optimal” decisions that may not result in a globally optimal tree.
- Doesn’t tend to work well if the classes are highly unbalanced.
- Doesn’t tend to work well with very small datasets.
When to stop?
If the number of features are too large, we’ll have a very large tree! Even, it easily leads to an overfitting problem. How to avoid them?
- Pruning: removing the branches that make use of features having low importance.
- Set a minimum number of training input to use on each leaf. If it doesn’t satisfy, we remove this leaf. In scikit-learn, use
min_samples_split. - Set the maximum depth of the tree. In scikit-learn, use
max_depth.
When we need to use Decision Tree?
- When explainability between variable is prioritised over accuracy. Otherwise, we tend to use Random Forest.
- When the data is more non-parametric in nature.
- When we want a simple model.
- When entire dataset and features can be used
- When we have limited computational power
- When we are not worried about accuracy on future datasets.
- When we are not worried about accuracy on future datasets.
Using Decision Tree Classifier with Scikit-learn
Load and create
Load the library,
from sklearn.tree import DecisionTreeClassifier
Create a decision tree (other parameters):
# The Gini impurity (default)
clf = DecisionTreeClassifier() # criterion='gini'
# The information gain (ID3)
clf = DecisionTreeClassifier(criterion='entropy')
An example,
from sklearn import tree
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
# predict
clf.predict([[2., 2.]])
# probability of each class
clf.predict_proba([[2., 2.]])
array([1])
array([[0., 1.]])
Plot and Save plots
Plot the tree (You may need to install Graphviz first. Don’t forget to add its installed folder to $path),
from IPython.display import Image
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None,
rounded=True,
filled=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
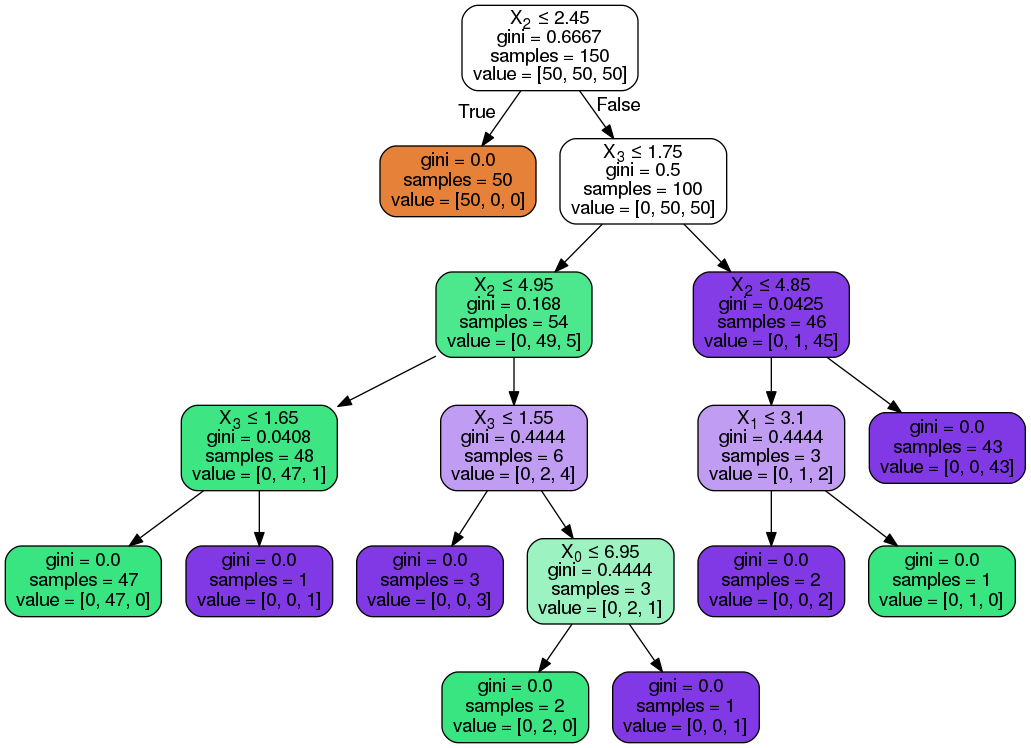
Save the tree (follows the codes in “plot the tree”)
graph.write_pdf("tree.pdf") # to pdf
graph.write_png("thi.png") # to png
References
- Scikit-learn. Decision Tree CLassifier official doc.
- Saed Sayad. Decision Tree - Classification.
- Tiep Vu. Bài 34: Decision Trees (1): Iterative Dichotomiser 3.
- Brian Ambielli. Information Entropy and Information Gain.
- Brian Ambielli. Gini Impurity (With Examples).
- Aurélien Géron. Hands-on Machine Learning with Scikit-Learn and TensorFlow, chapter 6.