
Last modified on 01 Oct 2021.
This is my note for the 2nd course of TensorFlow in Practice Specialization given by deeplearning.ai and taught by Laurence Moroney on Coursera.
👉 Check the codes on my Github.
👉 Official notebooks on Github.
👉 Go to course 1 - Intro to TensorFlow for AI, ML, DL.
👉 Go to course 3 - NLP in Tensorflow.
👉 Go to course 4 - Sequences, Time Series and Prediction.
Larger dataset
- Kaggle Dogs v Cats dataset - very famous dataset on Kaggle.
- Crop an image make the predict better!
- Make a larger dataset by rotating, scaling, cropping,…
Extract zip file + view image
# extract zip file
import zipfile
local_zip = 'file.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()
# show image
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()
image to np array
from keras.preprocessing import image
path = './image.png'
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
Plot loss and acc
history = model.fit(...)
acc = history.history[ 'accuracy' ]
val_acc = history.history[ 'val_accuracy' ]
loss = history.history[ 'loss' ]
val_loss = history.history['val_loss' ]
# plot accuracy
plt.plot ( epochs, acc )
plt.plot ( epochs, val_acc )
plt.title ('Training and validation acc')
plt.figure()
# plot loss function
plt.plot ( epochs, loss )
plt.plot ( epochs, val_loss )
plt.title ('Training and validation loss')
Cats vs dogs
os
base_dir = '/tmp/cats-v-dogs'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'training')
validation_dir = os.path.join(base_dir, 'testing')
os.mkdir(train_dir)
os.mkdir(validation_dir)
os.listdir(DIRECTORY) # gives you a listing of the contents of that directory
os.path.getsize(PATH) # gives you the size of the file
copyfile(source, destination) # copies a file from source to destination
random.sample(list, len(list)) # shuffles a list
Split data
Shuffle images and split/copy images to training/testing folder for each cat and dog.
def split_data(SOURCE, TRAINING, TESTING, SPLIT_SIZE):
lst_cat_imgs = os.listdir(SOURCE)
lst_cat_imgs = random.sample(lst_cat_imgs, len(lst_cat_imgs))
for file in lst_cat_imgs[:int(SPLIT_SIZE*len(lst_cat_imgs))]:
source_file = os.path.join(SOURCE, file)
destination_file = os.path.join(TRAINING, file)
if os.path.getsize(source_file) > 0:
copyfile(source_file, destination_file)
for file in lst_cat_imgs[int(SPLIT_SIZE*len(lst_cat_imgs)):]:
source_file = os.path.join(SOURCE, file)
destination_file = os.path.join(TESTING, file)
if os.path.getsize(source_file) > 0:
copyfile(source_file, destination_file)
CAT_SOURCE_DIR = "/tmp/PetImages/Cat/"
TRAINING_CATS_DIR = "/tmp/cats-v-dogs/training/cats/"
TESTING_CATS_DIR = "/tmp/cats-v-dogs/testing/cats/"
split_size = .9
split_data(CAT_SOURCE_DIR, TRAINING_CATS_DIR, TESTING_CATS_DIR, split_size)
Define model
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['acc'])
Generate data
TRAINING_DIR = "/tmp/cats-v-dogs/training/"
train_datagen = ImageDataGenerator( rescale = 1.0/255. )
train_generator = train_datagen.flow_from_directory(TRAINING_DIR,
batch_size=10,
class_mode='binary',
target_size=(150, 150))
# the same for validation
# output: Found 2700 images belonging to 2 classes.
Train
history = model.fit_generator(train_generator,
epochs=2,
verbose=1,
validation_data=validation_generator)
Image Augmentation
👉 Notebook: Cats v Dogs using augmentation & the final exercise (more data).
👉 Notebook: Human vs Horse using augmentation.
- Create multiple “other” images from original images without saving them to the memory + quickly.
- Image augmentation helps you avoid overfitting.
- Meaning of params, check this video.
- Broad set of images for BOTH training and testing sets!
- ImageDataGenerator on TF.
# The different from the code in the previous section!
train_datagen = ImageDataGenerator(
rescale=1./255, # rescale
rotation_range=40, # rotate randomly between 0 & 40 degrees (max 180)
width_shift_range=0.2, # offset horizontally 20%
height_shift_range=0.2, # offset vertically 20%
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest' # fill any pixel may been lost by the "nearest" ones
)
validation_datagen = ImageDataGenerator(rescale=1/255)
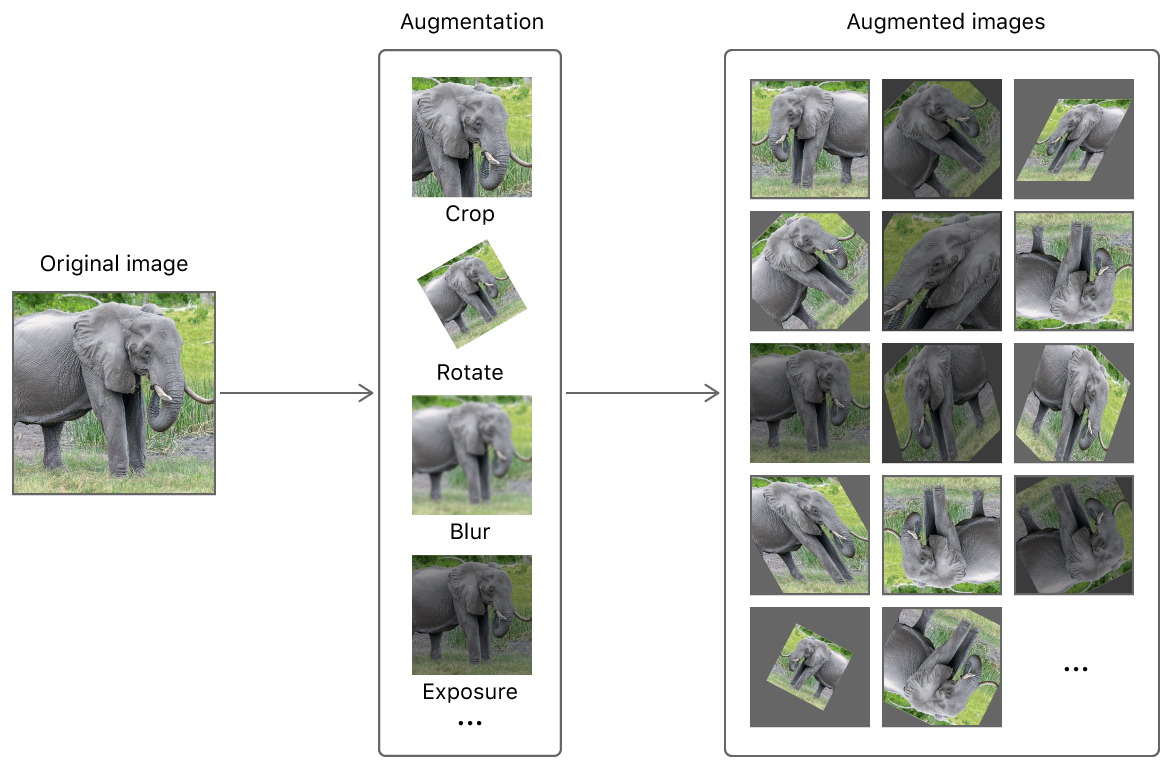 An illustration of image augmentation from apple.
An illustration of image augmentation from apple.
Transfer learning
👉 Notebook: Coding transfer learning from the inception mode. ➪ Video explains this notebook.
👉 Notebook: Horses v Humans using callBack, Augmentation, transfer learning (final exercise).
- Transfer learning = Taking existing model that’s trained on far more data + use the features that model learned.
- (Tensorflow tutorial) Transfer learning and fine-tuning
- Inception/GoogLeNet network: Inception Modules are used in CNN to allow for more efficient computation and deeper Networks through a dimensionality reduction with stacked 1x1 convolutions. The modules were designed to solve the problem of computational expense, as well as overfitting, among other issues. The solution, in short, is to take multiple kernel filter sizes within the CNN, and rather than stacking them sequentially, ordering them to operate on the same level. [ref] Check more in Refereces 1, 2, 3.
- Dropout: remove a random number of neurons in your NN. It works well because:
- neighboring neurons often end up with similar weights, which can lead to overfitting.
- a neuron can over-weigh the input from a neuron in the previous layer
from tensorflow.keras import layers
from tensorflow.keras import Model
# download snapshot of weights
from tensorflow.keras.applications.inception_v3 import InceptionV3
local_weights_file = '/tmp/inception_v3_weights.h5'
pre_trained_model = InceptionV3(
input_shape = (150, 150, 3),
include_top = False, # Inception v3 has a fully-connected
# layer at the top -> False to ignore
# it and get straight to the convolution.
weights = None # don't wana use built-in weights
)
pre_trained_model.load_weights(local_weights_file) # but use the snapshot downloaded
for layer in pre_trained_model.layers:
layer.trainable = False # lock pretrained layers
# they're not going to be trained
# with this code
# pre_trained_model.summary() # DON'T DO THAT, IT'S HUGE!!!
# By default, the output of the last layer will be 3x3 but we wanna
# get more info, so we grap layer "mixed7" from inception and take its output
# mixed7: output of a lot of conv that are 7x7
last_layer = pre_trained_model.get_layer('mixed7')
last_output = last_layer.output
from tensorflow.keras.optimizers import RMSprop
# Define a new model
x = layers.Flatten()(last_output) # Take the output (mixed7) from inception model
# last_output: look like dense model
# -> input of the new model
# Starting by flatting the input
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dropout(0.2)(x) # randomly remove 20% of neurons (avoid overfitting)
x = layers.Dense (1, activation='sigmoid')(x)
model = Model(pre_trained_model.input, x)
model.compile(optimizer = RMSprop(lr=0.0001),
loss = 'binary_crossentropy',
metrics = ['accuracy'])
Multi-class classification
👉 Notebook: Rock Paper Scissors.
👉 Notebook: MNIST.
- Rock-Paper-Scissors dataset (generated using CGI techniques)
The codes are quite the same as in the case of binary classification, the differences are
train_generator = train_datagen.flow_from_directory(
...
class_mode='categorical' # 'binary' for binary
)
model = tf.keras.models.Sequential([
...
tf.keras.layers.Dense(3, activation='softmax') # 'sigmoid' for binary
])
model.compile(
loss='categorical_crossentropy' # 'binary_lossentropy' for binary
)
More
- Applying Convolutions on top of our Deep neural network will make training ➪ It depends on many factors. It might make your training faster or slower, and a poorly designed Convolutional layer may even be less efficient than a plain DNN!
References
- Inception Network - Implementation Of GoogleNet In Keras
- ResNet, AlexNet, VGGNet, Inception: Understanding various architectures of Convolutional Networks – CV-Tricks.com
- Review: GoogLeNet (Inception v1)— Winner of ILSVRC 2014 (Image Classification)
- Transfer learning and fine-tuning - TensorFlow Core