
Last modified on 01 Oct 2021.
K-Means is the most popular clustering method any learner should know. In this note, we will understand the idea of KMeans and how to use it with Scikit-learn. Besides that, we also learn about its variants (K-medois, K-modes, K-medians).
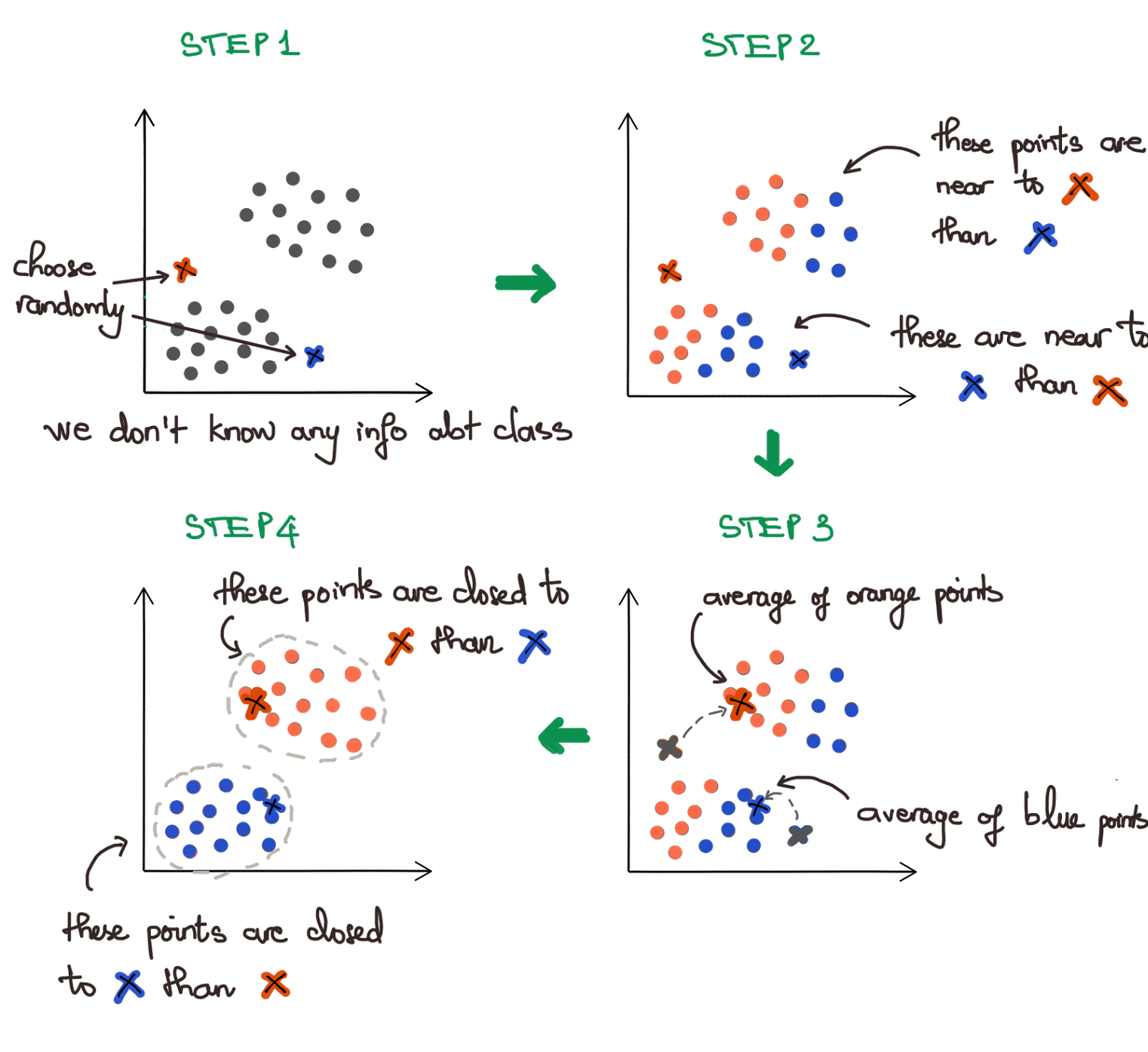
What’s the idea of K-Means?
- Randomly choose centroids ().
- Go through each example and assign them to the nearest centroid (assign class of that centroid).
- Move each centroid (of each class) to the average of data points having the same class with the centroid.
- Repeat 2 and 3 until convergence.
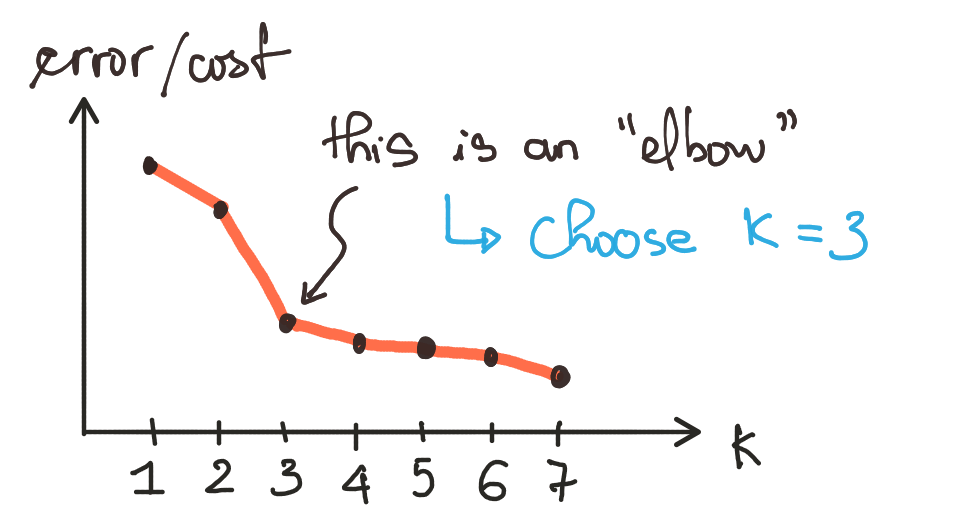
How to choose number of clusters?
Using “Elbow” method.
Discussion
- A type of Partitioning clustering.
- Not good if there are outliers, noise.
- The K-means method is sensitive to outliers ⇒ K-medoids clustering or PAM (Partitioning Around Medoids) is less sensitive to outliers[ref]
Using K-Means with Scikit-learn
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=10, random_state=0) # default k=8
kmeans.fit(X)
kmeans.predict(X)
# or
kmeans.fit_predict(X)
Some notable parameters (see full):
max_iter: Maximum number of iterations of the k-means algorithm for a single run.kmeans.labels_: show labels of each point.kmeans.cluster_centers_: cluster centroids.
K-Means in action
- K-Means clustering on the handwritten digits data.
- Image compression using K-Means – Open in HTML – Open in Colab.
K-medois clustering
References
- Luis Serrano – [Video] Clustering: K-means and Hierarchical.
- Andrew NG. – My raw note of the course “Machine Learning” on Coursera.