
Last modified on 01 Oct 2021.
Terminologies & fields of research
- Burst detection: An unexpectedly large number of events occurring within some certain temporal or spatial region is called a burst, suggesting unusual behaviors or activities.
- Time Series Regression: [ref] Time series regression is a statistical method for predicting a future response based on the response history (known as autoregressive dynamics) and the transfer of dynamics from relevant predictors. Time series regression can help you understand and predict the behavior of dynamic systems from experimental or observational data. Time series regression is commonly used for modeling and forecasting of economic, financial, and biological systems.
- Time Series Classification: [ref]
Time series classification deals with classifying the data points over the time based on its’ behavior. There can be data sets which behave in an abnormal manner when comparing with other data sets. Identifying unusual and anomalous time series is becoming increasingly common for organizations
- [ref] Time series classification data differs from a regular classification problem since the attributes have an ordered sequence.
- Anomaly Detection:
- A part in the same time series.
- Finding one or more time series which are different from others.
- Some abnormal points in the same time series.
- Applied for both univariate and multivariate time series.
Read_CSV
More here.
df_13 = pd.read_csv(path_file,
index_col='timestamp',
parse_dates=True, # index contains dates
infer_datetime_format=True, # auto regconize format
cache_dates=True) # faster
Find the windows of time series
Suppose we have data like in below, we wanna find the common length interval of all groups.
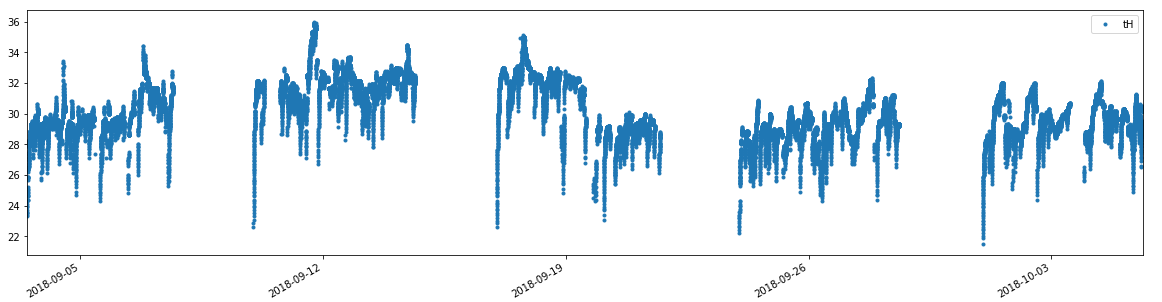
# find the biggest gap
df['date'].diff().max()
# 4 biggest gaps
df['date'].diff().sort_values().iloc[-5:]
# starting of each window (the gap used to separate windows is '1D')
w_starts = df.reset_index()[~(df['date'].diff() < pd.to_timedelta('1D'))].index
# ending of each window
w_ends = (w_starts[1:] - 1).append(pd.Index([df.shape[0]-1]))
# count the number of windows
len(w_starts)
# the biggest/average window size (in points)
(w_ends - w_starts).max()
(w_ends - w_starts).values.mean()
# the biggest window size (in time range)
pd.Timedelta((df.iloc[w_ends]['date'] - df.iloc[w_starts]['date']).max(), unit='ns')
If you wanna add a window column to the original dataframe,
df_tmp = df.copy()
w_idx = 0
for i in range(w_starts.shape[0]):
df_tmp.loc[w_starts[i]:(w_ends[i]+1), 'window'] = w_idx
w_idx += 1
df_tmp.window = df_tmp.window.astype(int) # convert dtype to int64
There are other cases need to be considered,
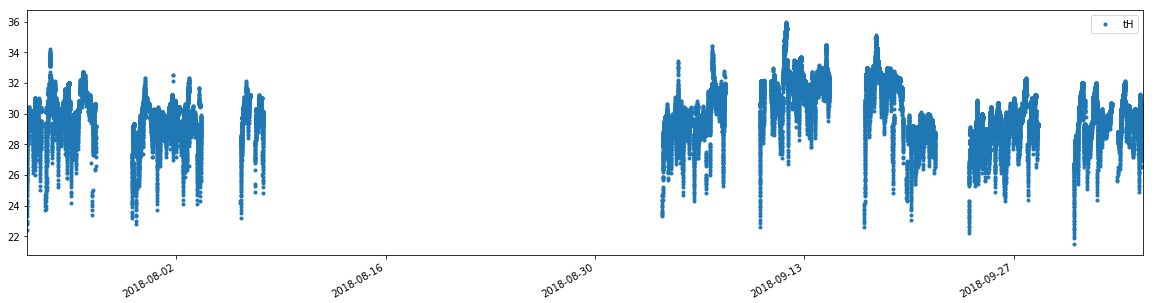 The gaps are not regular
The gaps are not regular
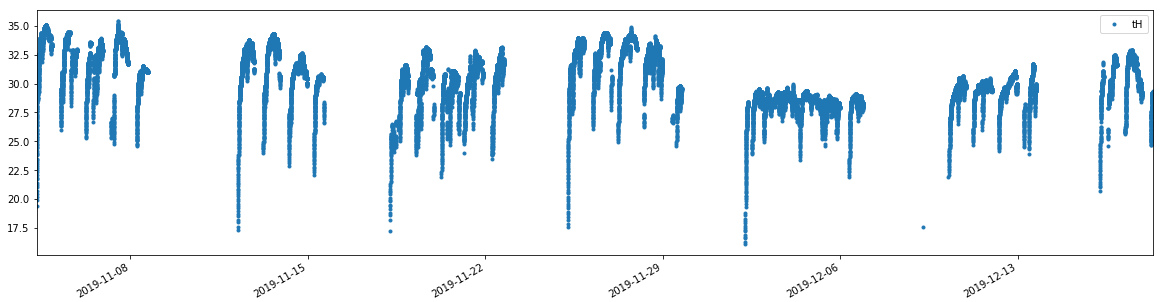 If we choose the gaps (to determine the windows) too small, there are some windows have only 1 point like in this case.
If we choose the gaps (to determine the windows) too small, there are some windows have only 1 point like in this case.
Find the gap’s threshold automatically,
from sklearn.cluster import MeanShift
def find_gap_auto(df):
X = df['date'].diff().unique()
X = X[~np.isnat(X)] # remove 'NaT'
X.sort()
X = X.reshape(-1,1)
clustering = MeanShift().fit(X)
labels = clustering.labels_
cluster_min = labels[0]
gap = pd.to_timedelta((X[labels!=cluster_min].min() + X[labels==cluster_min].max())/2)
return gap
•Notes with this notation aren't good enough. They are being updated. If you can see this, you are so smart. ;)